 FIGURE 8.1 Opcode table entry (each
opcode table entry contains the symbolic opcode, numeric opcode and field
specification, and a type field).
FIGURE 8.1 Opcode table entry (each
opcode table entry contains the symbolic opcode, numeric opcode and field
specification, and a type field).

Assemblers are the simplest of a class of systems programs called translators. A translator is simply a program which translates from one (computer) language to another (computer) language. In the case of an assembler, the translation is from assembly language to object language (which is input to a loader). Notice that an assembler, like all translators, adds nothing to the program which it translates, but merely changes the program from one form to another. The use of a translator allows a program to be written in a form which is convenient for the programmer, and then the program is translated into a form convenient for the computer.
Assembly language is almost the same as machine language. The major difference is that assembly language allows the declaration and use of symbols to stand for the numeric values to be used for opcodes, fields, and addresses. An assembler inputs a program written in assembly language, and translates all of the symbols in the input into numeric values, creating an output object module, suitable for loading. The object module is output to a storage device which allows the assembled program to be read back into the computer by the loader.
This is an external view of an assembler. Now we turn our attention to an internal view, in order to see how the assembler is structured internally to translate assembly programs into object programs.
Appropriate data structures can make a program much easier to understand, and the data structures for an assembler are crucial to its programming. An assembler must translate two different kinds of symbols: assembler-defined symbols and programmer-defined symbols. The assembler-defined symbols are mnemonics for the machine instructions and pseudo-instructions. Programmer-defined symbols are the symbols which the programmer defines in the label field of statements in his program. These two kinds of symbols are translated by two different tables: the opcode table, and the symbol table.
The opcode table contains one entry for each assembly language mnemonic. Each entry needs to contain several fields. One field is the character code of the symbolic opcode. In addition, for machine instructions, each entry would contain the numeric opcode and default field specification. These are the minimal pieces of information needed. With an opcode table like this, it is possible to search for a symbolic opcode and find the correct numeric opcode and field specification.
Pseudo instructions require a little more thought. There is no numeric opcode or field specification associated with a pseudo-instruction; rather, there is a function which must be performed for each pseudo-instruction. This can be encoded in several ways. One method is to include in the opcode table, a type field. The type field is used to separate pseudo-instructions from machine instructions and to separate the various pseudo-instructions. Different things need to be done for each of the different pseudo-instructions, and so each has its own type. All machine instructions can be handled the same, however, so only one type is needed for them. One possible type assignment is then,
| type | instruction class | |
|---|---|---|
| 1 | Machine instruction | |
| 2 | ORIG pseudo-instruction | |
| 3 | CON pseudo-instruction | |
| 4 | ALF pseudo-instruction | |
| 5 | EQU pseudo-instruction | |
| 6 | END pseudo-instruction. |
Other type assignments are also possible. For example, in the above assignment, all machine instructions have one type, and are treated equally. This allows both instructions such as
Another approach to separating the pseudo-instructions in the opcode table is to consider how the type field of the above discussion would be used. It would be used in a jump table. In this case, rather than using the type to specify the code address through a jump table, we could store the address of the code directly in the opcode table. In each opcode table entry, we can store the address of the code to be executed for proper treatment of this instruction, whether it is a machine instruction or a pseudo-instruction. This is a commonly used technique for assemblers.
Other opcode table structures are possible also. Some assemblers have separate tables for machine instructions and for pseudo-instructions. Others will use a type field of one bit to distinguish between machine instructions and pseudo-instructions, and then store a numeric opcode and field specification for the machine instructions or an address of code to execute for pseudo-instructions.
For simplicity, let us assume that we store, for each entry, the symbolic mnemonic, numeric opcode, default field specification and a type, as defined above. For pseudo-instructions, the numeric opcode and default field specification of the entry will be ignored. How should we organize our opcode table entries? The opcode table should be organized to minimize both search time and table space. These two goals may not be achievable at the same time. The fastest access to table entries would require that each field of an entry be in the same relative position of a memory word, such as in Figure 8.1. But notice that, in this case, three bytes of each entry are unused, so that the table includes a large amount of wasted space. (Actually, three bytes, two signs, and the upper three bits of the type byte are unused.) To save this space would require more code and longer execution times for packing and unpacking operations. Thus, to save time it seems wise to accept this wasted space in the opcode table.
FIGURE 8.1 Opcode table entry (each
opcode table entry contains the symbolic opcode, numeric opcode and field
specification, and a type field).
To a great extent this wasted space is due to the design of the assembly language mnemonics. If the mnemonics had been defined as a maximum of three characters (instead of four), it would have been possible to store the mnemonic, field specifications, and opcode in one word. The sign bit would be "+"for machine instructions and "-" for pseudo-instructions. Pseudo instructions could have a type field or address in the lower bytes while machine instructions would store opcode and field specifications. On the other hand, once the decision is made that four character mnemonics are needed, then it is necessary to go to a multi-word opcode table entry. In this case, we could allow mnemonics of up to seven characters, by using the currently unused three bytes of the opcode table entry. On the other hand, there may be no desire to have opcode mnemonics of more than four characters; mnemonics should be short.
Another consideration is the order of entries in the table. This relates to the expected search time to find a particular entry in the table. The simplest search is a linear search starting at one end of the table and working towards the other end until a match is found (or the end of the table is reached). In this case, one should organize the table so that the more common mnemonics will be compared first. If, as expected, the LDA mnemonic is the most common instruction, then it should be put at the end of the table which is searched first.
Rather than use a linear search, it can be noted that the opcode table is a static structure; it does not change. The opcode table is like a dictionary explaining the numeric meaning of symbolic opcodes. Like a dictionary, it can be usefully organized in an alphabetical order. By ordering the entries, the table can be searched with a binary search. A binary search is the method commonly used to look for an entry in a dictionary, telephone book, or encyclopedia. First the middle of the book is compared with the entry being searched for (the search key). If the search key is smaller than the middle entry, then the key must be in the first half of the book, if it is larger it must be in the latter half of the book. After this comparison, the same idea can be repeated on the half of the book which still needs to be searched. Each comparison splits the remaining section of the book in half.
In MIX, this might be coded as follows. Location KEY contains the value for which we are searching. LOW contains our low index, while HIGH contains our high index. Initially, LOW would point to the first entry of the table; HIGH would point to the last entry. The search loop would then be
A binary search is not always the best search method to use. Each time through, the search loop cuts the size of the table yet to be searched in half. In general, a table of size 2n will take about n comparisons to find an entry. Thus, a table of size 32 will take only 5 comparisons, while for a linear search, it is normally assumed, that on the average, half of the table must be searched, resulting in 16 comparisons. Thus, the binary search almost always requires fewer executions of its search loop than a linear search. However, notice that the binary search requires considerably more computation per comparison than a linear search. The binary search loop requires about 35 time units per comparison while a linear search can require only 5 time units. Thus, for a table of size 32, the binary search takes 5 comparisons at 35 time units each, for 175 time units, while the linear search takes 16 comparisons at 5 time units each for 80 time units. This is not to say that a binary search should never be used. For a table of size 128, a binary search will take about 245 (= 7 × 35) time units, while a linear search will take 320 (= 64 × 5). Thus, for a large table a binary search is better. Also, if a shift (SRB) could be used instead of the divide, the time per loop could be cut by 11 time units, making the binary search better. Since there are around 150 MIX opcodes, we use a binary search for the opcode table.
The opcode table is used to translate the assembler-defined symbols into their numeric equivalents; the symbol table is used to translate programmer-defined symbols into their numeric equivalents. Thus, these two tables can be quite alike. A symbol table, like an opcode table, is a table of many entries, one entry for each programmer-defined symbol. Each entry is composed of several fields.
For the symbol table, only two fields are basically needed. It is necessary to store the symbol and the value of the symbol. A symbol in a MIXAL program can be up to 10 characters in length. This requires two MIX words. In addition, the value of the symbol can be up to five bytes plus sign, requiring another MIX word. Thus, each entry in the symbol table takes at least three words. Additional fields may be added for some assemblers. A bit may be needed to indicate if the symbol has been defined or is undefined (i.e., a forward reference). Another bit may specify whether the symbol is an absolute symbol or a relative symbol (depending on whether the output is to be used with a relocatable or absolute loader). Other fields may also be included in a symbol table entry, but for the moment let us use only the two fields, for the symbol and its value.
As with the opcode table, the organization of the symbol table is very important for proper use. But the symbol table differs from the opcode table in one important respect: it is dynamic. The opcode table was static; it is never changed, neither during nor between executions of the assembler. It is the same for each and every assembly program for the entire assembly process. The symbol table is dynamic; each program has its own set of symbols with their own values and new symbols are added to the symbol table as the assembly process proceeds. Initially the symbol table is empty; no symbols have been defined. By the time assembly is completed, however, all symbols in the program have been entered into the symbol table.
This requires the definition of two subroutines to manipulate the symbol table: a search routine and an enter routine. The search routine searches the symbol table for a symbol (its search key) and returns its value (or an index into the table to its value). The enter subroutine puts a new symbol and its value into the table.
These two subroutines need to be designed together, since both of them affect the symbol table. A binary search might be quite efficient, but it requires that the table be kept ordered. This means that the enter subroutine would have to adjust the table for each new entry, so that the table was always sorted into the correct order. Thus, although a binary search might be quick, the combination of a binary search plus an ordered enter might be very expensive.
Also consider that a linear search is more efficient than a binary search for small tables. Many assembly language programs have less than 200 different symbols, and so a linear search may be quite reasonable. A linear search allows the enter routine to simply put any new symbol and its value at the end of the table. Thus, both the search and enter routines are simple.
Many other table management techniques have been considered and are used. Some of these are quite complex and useful only for special cases. Others have wide applicability. One of the most commonly used techniques is hashing. The objective of hashing is quite simple. Rather than have to search for a symbol at all, we would prefer to be able to compute the location in the table of a symbol from the symbol itself. Then, to enter a symbol, we compute where it should go, and define that entry. For accessing, we compute the address of the entry and use the value stored in the table at that location.
As a simple example, assume that all of our symbols were one-letter symbols (A, B, C, …, Z). Then if we simply allocated a symbol table of 26 locations, we could index directly to a table entry for each symbol by using its character code for an index. No searching would be needed. If our symbols were any two-letter symbols, we could apply the same idea if we had a symbol table of 676 (= 26 × 26) entries, where our hash function would be to multiply the character code of the first letter by 26 and add the character code of the second (and subtract 26 to normalize). However, for three-letter symbols, we would need 17,576 spaces in our symbol table. This is clearly impossible. (Our MIX memory is only 4000 words long.) It also is not necessary, since we assume that at most only a few hundred symbols will be used in each different assembly program. What is needed is a function which produces an address for each different symbol, but maps them all into a table of several hundred words.
Many different hashing functions can be used. For example, we can add together the character codes for the different characters of the symbol, or multiply them, or shift some of them a few bits and exclusive-OR them with the other characters, or whatever we wish. Then, after we have hashed up the input characters to get some weird number, we can divide by the length of the table and use the remainder. The remainder is guaranteed to be between 0 and the length of the table and hence can be used as an index into the table. For a binary machine and a table whose length is a power of two, the division can be done by simply masking the low-order bits.
The objective of all this calculation is to arrive at an address for a symbol which hopefully is unique for each symbol. But since there are millions of 10-character symbols, and only a few hundred table entries, it must be the case that two different symbols may hash into the same table entry. For example, if we use a hash function which adds together the character codes of the letters in the symbol, then both EVIL and LIVE will hash to the same location. This is called a collision. The simplest solution to this problem is to then search through successive entries in the table, until an empty table entry is found. (If the end of the table is found, start over at the beginning).
The search and enter routines are now straightforward. To enter a new symbol, compute its hash function, and find an empty entry in the table. Enter the new symbol in this entry. To search for a symbol, compute its hash function and search the table starting at that entry. If an empty entry is found, the symbol is not in the table. Otherwise, it will be found before the first empty location.
The problem with using hashing is defining a good hash function. A good hash function will result in very few collisions. This means that both the search and enter routines will be very fast. In the worst case, all symbols will hash to the same location and a linear search will result. Hashing is sometimes also used for opcode tables, where, since the opcode table is static and known, a hashing function can be constructed which guarantees no collisions.
More about hashing can be found in the paper by Morris (1968), or in Knuth (1973), Volume 3.
The opcode table and the symbol table are the major data structures for an assembler, but not the only ones. The other data structures differ from assembler to assembler, depending upon the design of the assembly language and the assembler.
A buffer is probably needed to hold each input assembly language statement, and another buffer is needed to hold the line image corresponding to that statement for the listing of the program. In addition buffers may be needed to create the object module output for the loader, and to perform double buffering in order to maximize CPU-I/O overlap. Various variables are needed to count the number of cards read, the number of symbols in the symbol table, and so on.
One variable in particular is important. This is the location counter. The location counter is a variable which stores the address of the location into which the current instruction is to be loaded. The value of the location counter is used whenever the symbol "*" is used, and this value can be set by the ORIG pseudo-instruction. Normally the value of the location counter is increased by one after each instruction is assembled, in order to load the next instruction into the next location in memory. The value of the location counter for each instruction is used to instruct the loader where to load the instruction.
With a familiarity with the basic data structures of an assembler (the opcode table, the symbol table, and the location counter), we can now describe the general flow of an assembler. Each input assembly statement, each card, is handled separately, so our most general flow would be simply, "Process each card until an END pseudo-instruction is found."
More specifically, consider what kind of processing is needed for each card:
This much of the assembly process is common to all of the input cards. The important processing is in step 3, where each card is processed according to its type. This level of the assembler provides an organizational framework for further development.
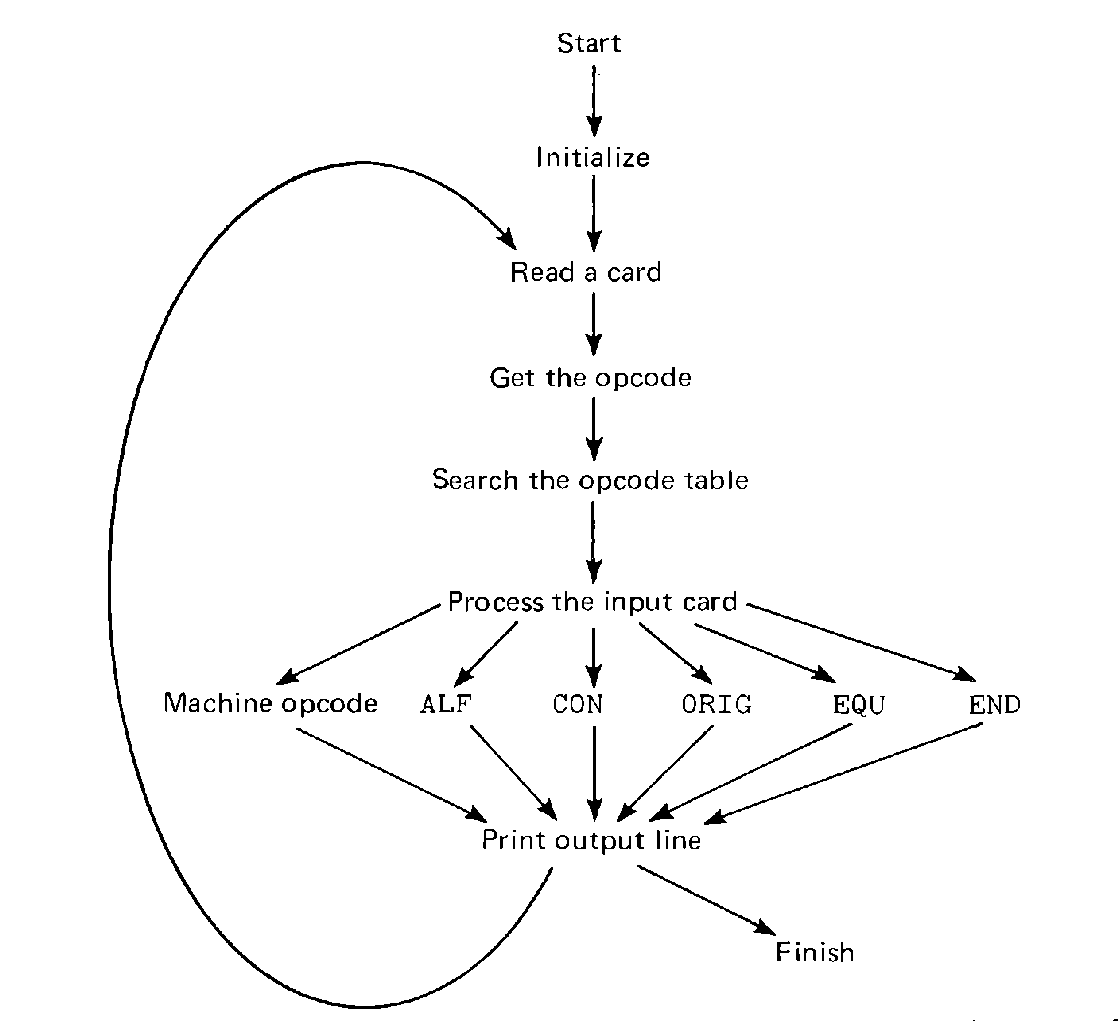 FIGURE 8.2 The general flow of an assembler (for
MIXAL). Refinement of this general design resulted in the
assembler described in Section 8.3.
FIGURE 8.2 The general flow of an assembler (for
MIXAL). Refinement of this general design resulted in the
assembler described in Section 8.3.
Continuing then, what processing needs to be done for each type of opcode? Consider a machine language instruction. For a machine language instruction, we need to determine the contents of each of the four fields of a machine language instruction. In addition, we must define any label which is in the label field. Let us define the label first. Defining a label is simply a matter of entering the label (if any) in the label field of the assembly language statement into the symbol table with a value which is the value of the current location counter.
Now we need to determine the fields of the machine language instruction. The opcode field (byte 5:5) and the field specification (byte 4:4) are available in the opcode table entry which has already been found. To find the other fields (address and index), let us assume that we have a subroutine which will evaluate an expression. This subroutine will be written later. Then, to define the address field, we call our expression evaluator. The value it returns is the contents of the address field (bytes 0:2). When it returns, we check the next character. If the next character is a comma ",", then an index part follows and we call the expression evaluator again to evaluate the index part. If the next character is not a comma, then the index part is zero (default). When the index has been processed, we check the next character. If it is a left parenthesis, then the expression which follows is a field specification, and we call the expression evaluator again. Otherwise, we use the default specification from the opcode table.
Basically, we have defined an assembly language statement to be of the form
The processing for each pseudo-instruction is generally easy.
For an ORIG instruction, no code is generated. Rather, only two things need be done. First, if a label is present, it should be defined. Its value is the value of the location counter. Second, the expression in the operand field is evaluated and the value of the expression is stored as the new value of the location counter. We can use the same expression evaluator that is used for evaluation of the machine language operands.
The EQU pseudo-instruction is similarly straightforward. For an EQU instruction, we first evaluate the operand expression (using the expression evaluator as before), and then we enter the symbol in the label field into the symbol table with a value of the expression.
The ALF pseudo-instruction is even easier. In this case we first define the label of the instruction. Then we pick up the character code of the five characters of the ALF operand and issue them as a generated word, incrementing the location counter after we do so.
The most complicated pseudo-instruction is probably the CON instruction. The general form of this instruction is
Once the operand of the CON instruction has been generated, it can be output for loading and the location counter can be incremented.
The last pseudo-instruction the assembler will encounter is the END pseudo-instruction. For this pseudo-instruction, we first define the label. Then we evaluate the operand expression and output it to the loader as the starting address.
As you can see, each pseudo-instruction requires its own section of code for correct processing, and the pseudo-instruction processing for each is different. However, the processing for each individual pseudo-instruction, considered separately, is not overly complicated. The basic functions used in processing all assembly language instructions involve defining labels, evaluating expressions, and generating code. The first of these was discussed in Section 8.1, so now let us consider the evaluation of expressions.
An expression in MIXAL is composed of two basic elements: operands and operators. The operators are addition (+), subtraction (-), multiplication (*), division (/), and "multiplication by eight and addition" (:). The operands are of three types: numbers, symbols, and "*". Numbers have a value which is defined by the number itself, interpreted as a decimal number. Symbols are defined by the value field of their symbol table entry. The value of * is the value of the location counter.
The operators are applied to the operands strictly left to right, without precedence. This allows a very simple expression evaluation routine whose code is basically as follows.
And that is all that there is to it. Expressions for MIXAL have been defined in such a way that their evaluation is quite simple. Only one problem has been ignored. That problem is forward references.
The forward referencing problem arises in a very simple way: the expression evaluator attempts to evaluate an operand which is a symbol by searching the symbol table, and finds that the symbol is not in the symbol table. The symbol is not defined, the expression cannot be evaluated, and the assembly language statement cannot be assembled. What can be done?
One solution is to disallow forward references. MIXAL uses this approach in several places. No pseudo-instruction can make a forward reference. Forward references are not allowed in the index or field specification fields of an instruction. However, a restriction to no forward references would be extremely inconvenient and so two other solutions are more commonly used for allowing some forward references. These two solutions result in two classes of assemblers: one-pass assemblers and two-pass assemblers. Since two-pass assemblers are conceptually simpler, we consider them first.
A two-pass assembler makes two passes over the input program. That is, it reads the program twice. On the first pass, the assembler constructs the symbol table. On the second pass, the complete symbol table is used to allow expressions to be evaluated without problems due to forward references. If any symbol is not in the symbol table during an expression evaluation, it is an error, not a forward reference.
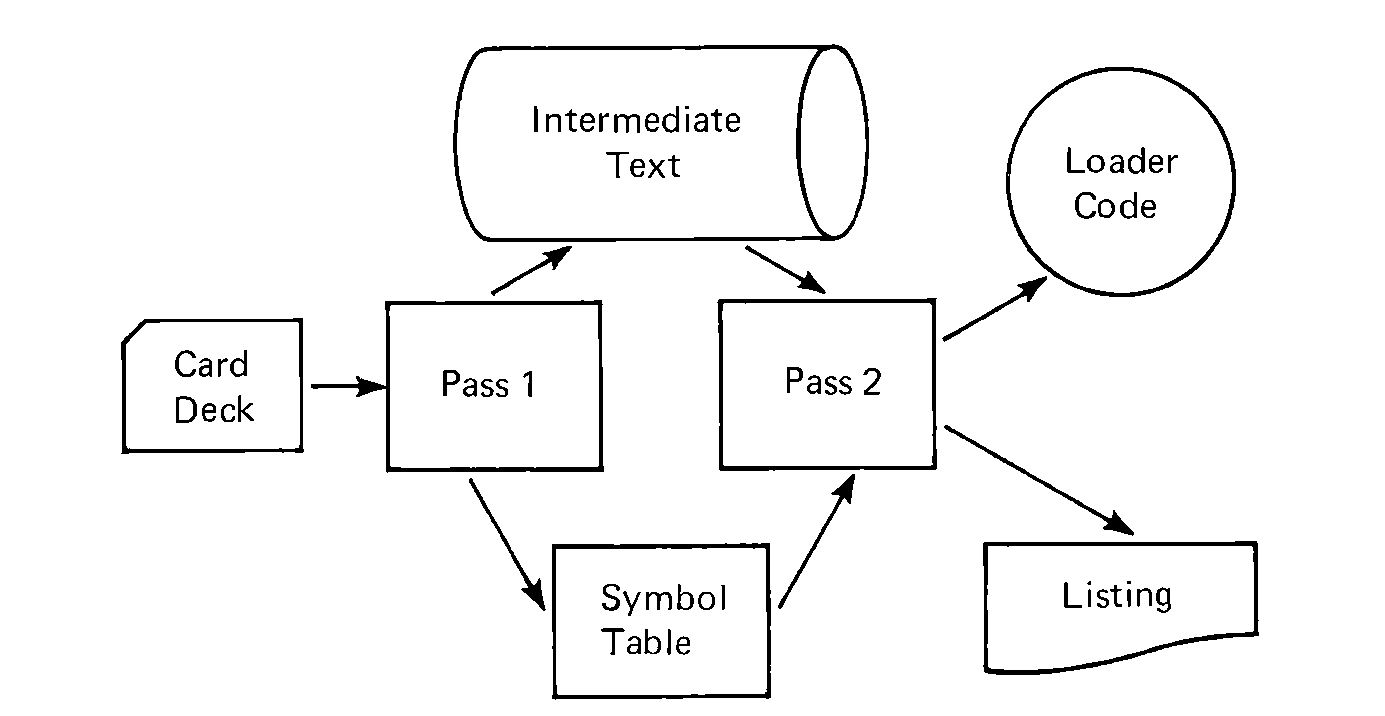 FIGURE 8.3 A block diagram of a two-pass assembler. Pass 1
produces a symbol table and a copy of the input source program
for pass 2. Pass 2 produces loader code and a listing.
FIGURE 8.3 A block diagram of a two-pass assembler. Pass 1
produces a symbol table and a copy of the input source program
for pass 2. Pass 2 produces loader code and a listing.
Briefly, for a two-pass assembler, the first pass constructs the symbol table; the second pass generates object code. This causes a major change in the basic flow of an assembler, and results in another important data structure: the intermediate text. Since two passes are being made over the input assembly language, it is necessary to save a copy of the program read for pass 1, to be used in pass two. Notice that since the assembly listing includes the generated machine language code, and the machine language code is not produced until pass 2, the assembly listing is not produced until pass 2. This requires storing the entire input program, including comments, and so forth, which are not needed by the assembler during pass 2.
The intermediate text can be stored in several ways. The best storage location would be in main memory. However, since MIX memory is so small, this technique is not possible on the MIX computer. On other machines, with more memory, this technique is sometimes used for very small programs. Another approach, used for very small machines, is to simply require the programmer to read his program into the computer twice, once for pass 1, and again for pass 2. A PDP-8 assembler has used this approach, even going so far as to require the program be read in a third time if a listing is desired.
A more common solution is to store the intermediate text on a secondary storage device, such as tape, drum, or disk. During pass 1, the original program is read in, and copied to secondary storage as the symbol table is constructed. Between passes, the device is repositioned (rewound for tapes, or the head moved back to the first track for moving head disk or drum). During pass 2, the program is read back from secondary storage for object code generation and printing a listing. (Notice that precautions should be taken that the same tape is not used for both storage of the intermediate text input for pass 2 and the storage of the object code produced as output from pass 2 for the loader.)
The general flow of a two-pass assembler differs from that given above, in that now each card must be processed twice, with different processing on each pass. It is also still necessary to process each type of card differently, depending upon its opcode type. This applies to both pass 1 and pass 2.
For machine instructions, pass 1 processing involves simply defining the label (if any) and incrementing the location counter by one. ALF and CON pseudo-instructions are handled in the same way. ORIG statements must be handled exactly as we described above, however, in order for the location counter to have the correct value for defining labels. Similarly, EQU statements must also be treated on pass 1. This means that no matter what approach is used, no forward references can be allowed in ORIG or EQU statements, since both are processed during pass 1. The END statement needs to have its label defined and then should jump to pass 2 for further processing.
During pass 2, EQU statements can be treated as comments. The label field can likewise be ignored. ALF, CON, and machine instructions will be processed as described above, as will the END statement.
The need to make two passes over the program can result in considerable duplication in code and computation during pass 1 and pass 2. For example, on both passes, we need to find the type of the opcode; on pass 1, to be able to treat ORIG, EQU, and END statements; on pass 2, for all types. This can result in having to search the opcode table twice for each assembly language statement. To prevent this, we need only save the index into the opcode table of the opcode (once it is found during pass 1) with each instruction. Also, consider that since the operand "*" may be used in the expressions evaluated during pass 2, it is necessary to duplicate during pass 2 the efforts of pass 1 to define the location counter, unless we can simply store with each assembly language statement the value of the location counter for that statement.
These considerations can result in extending the definition of the intermediate text to be more than simply the input to pass 1. Each input assembly language statement can be a record containing (at least) the following fields.
Even more can be computed during pass 1. For example, ALF and CON statements can be completely processed during pass 1. The opcode field, field specification, and index field for a machine instruction can be easily computed during pass 1, and most of the time the address field, too, can be processed on pass 1. It is only the occasional forward reference which causes a second pass to be needed. Most two-pass assemblers store a partially digested form of the input source program as their intermediate text for pass 2.
Assemblers, like loaders, are almost always I/O-bound programs, since the time to read a card generally far exceeds the time to assemble it. Thus, requiring two passes means an assembler takes twice as long to execute as an assembler which only uses one pass.
It is these considerations which have given rise to one-pass assemblers. A one-pass assembler does everything in one pass through the program, much as described earlier. The only problem with a one-pass assembler is caused by forward references, of course. The solutions to this problem are the same as were presented earlier for one-pass relocatable linking loaders: Use-tables or Chaining.
In either case, Use-table or Chaining, it is not possible to completely generate the machine language statement which corresponds to an assembly language statement; the address field cannot always be defined. Thus, some later program must fix-up those instructions with forward reference. In a two-pass assembler, this program is pass 2. In a one-pass assembler, there is no second pass, and so the program which must fix-up the forward references is the loader. The loader resolves forward references for a one-pass assembler.
If Use-tables are used to solve the future reference problem, then the assembler keeps track of all forward references to each symbol. After the value of the symbol is defined, the assembler generates special loader instructions to tell the loader the addresses of all forward references to a symbol and its correct value. When the loader encounters these special instructions during loading, it will fix-up the address field of the forward reference instruction to have the correct value.
A variation of this same idea is to use chaining. With chaining, the entries in the Use-table are kept in the address fields of the instructions which forward reference symbols. Only the address of the most recent use must be kept. When a new forward reference is encountered, the address of the previous reference is used, and the address of the most recent reference is kept. When a symbol is defined which has been forward referenced (or at the end of the program), special instructions are again issued to the loader to fix-up the chains which have been produced.
Variations on this basic theme are possible also. For example, if the standard loader will not fix-up forward references, it would be possible for the assembler to generate some special instructions which would be executed first, after loading, but before the assembled program is executed to fix-up forward references. But the basic idea remains the same: a one-pass assembler generates its object code for the loader in such a way that the loader, or the loaded program itself, will fix-up forward references.
Throughout the discussion of the assembly process, so far, we have ignored many of the (relatively) minor points concerning the writing of an assembler. One of the most visible of these considerations is the assembly listing. The assembly listing gives, for each input assembly line, the correspondingly generated machine language code. Notice, however, that not all assembly language statements result in the generation of machine language code, and not all code is meant to be interpreted in the same way (some are instructions, others numbers or character code).
For a machine language statement, useful information which can be listed includes the card image, card number, location counter, and generated code, broken down by field. For an ORIG, EQU, or END statement, on the other hand, no code is generated, but the value of the operand expression would be of interest. A CON or ALF statement would need to list the generated word, but as a number, not broken down by fields, as an instruction. Forward references in a one-pass assembler might be specially marked, as might a relocatable address field in a relocatable assembly program.
In addition to the listing of the input assembly, some assemblers also print a copy of their symbol table after it is completed. This symbol table listing would include the defined symbols, their values and perhaps the input card number where they were defined. Some assemblers will also produce a cross reference listing, which is a listing, for each symbol, of the card numbers or memory locations in the program of all references to that symbol. Most symbol table listings and cross reference listings are ordered alphabetically by symbol to aid in finding a particular symbol.
Another concern is the problem of errors. Many programs have assembler errors in them. These are errors not in what the program does, but in its form. These can be caused by mistakes in writing the program, or in the transcription of the program into a machine-readable form, like keypunching. The assembler must check for errors at all times. Typical errors include, multiply-defined symbols (using the same symbol in the label field twice), undefined symbols (using a symbol in the operand field of a statement, but never defining it in the label field), undefined opcodes (opcode cannot be found in the opcode table), illegal use of a forward reference, an illegal value for a field (index or field specification value not between 0 and 63, or address expression not between -4095 and +4095), and so on.
For each possible error, two things must be decided: (1) how to notify the programmer of the error, and (2) what to do next. The notification is often simplest. An error symbol or error number is associated with each type of error. The degree of specification of the exact error varies. One approach is to simply declare "error in assembly" or "error in xxxx part", where xxxx may be replaced by "label", "opcode", or "operand." However, these approaches may not give the programmer enough information to find and correct the error. The opposite approach is also sometimes taken, over-specifying the error to the extent that the user's manual lists thousands of errors, most of which are equivalent (from the point of view of the programmer), and with each error highly unlikely.
More typically, the major errors are classified and identified, while more obscure and unlikely errors are grouped into a category such as "syntax error in operand part." The listing line format may include a field in which errors are flagged, or a statement with an error may be followed by an error message.
In any case, the writer of the assembler must check for all possible errors in the input assembly program. If one is found, a decision must be made as to what to do next. This often may depend upon the type of error which is found, and the error handling code for each error is generally different. For a multiply-defined label, the second definition is often ignored, or the latest definition may always be used. An undefined opcode may be assumed to be a comment card, or treated like a HLT or NOP instruction. Illegal values for any of the fields of an instruction can result in default values being used.
Whatever the specific approach taken to a specific error, a general approach must also be taken. From the way in which an assembly language program is written, each input statement is basically a separate item to be translated. Thus, an error in one statement still allows the assembler to continue its assembly of the remaining program by simply ignoring the statement which is in error. This is in contrast to some systems which cease all operations whenever the first error is found. An assembler can always continue with the next card, after an error is found in the current card.
A more subtle point is whether or not an assembler should attempt to continue assembling the card in which the error occurs. If the opcode is undefined, the assembler may misinterpret the label field or operand field, causing it to appear that there are more (or fewer) errors than exist, once the incorrect opcode is corrected. (For example, a typing error on an ALF card may result in an undefined opcode. If the operand field of the incorrect ALF is treated as if the opcode were a machine instruction, then the character sequence for the ALF may result in an apparent reference to an undefined symbol.) On the other hand, attempting to continue assembling a card after an error may identify additional errors which would save the programmer several extra assemblies to find.
The discussion of loaders and linkers in Chapter 7 mentioned several differences between an assembly language which is used with a relocatable loader and an assembly language for an absolute loader. These differences show up in the assembly language in terms of the pseudo-instructions available and also in restrictions on the types of expressions (absolute or relocatable) which can be used.
It should be relatively obvious that the changes in the assembler for absolute and relocatable programs are not major changes, but consist mainly in the writing of some new code to handle the new pseudo-instructions and some changes in code generation format to match the input expected by a relocatable loader. Extra tables may be required for listing entry points and external symbols, and a type field will need to be added to the symbol table to distinguish between absolute symbols, relocatable symbols, entry points, and external symbols.
Another type of assembler, in addition to relocatable versus absolute and one-pass versus two-pass, is the load-and-go assembler. These assemblers are typically used on large computers for small programs (like programs written by students just learning the assembly language). The idea of a load-and-go assembler is to both assemble and load a program at the same time. The major problem with this, on most machines, including the MIX computer, is the size of memory and the size of the assembler. There is simply not enough room for both a program and the assembler in memory at the same time.
However, for a simple assembly language, giving rise to a simple and small assembler, and with a large memory, it is possible to write an assembler which, rather than generating loader code, loads the program directly into memory as it is assembled. The assembler acts as both an assembler and a loader at the same time. These load-and-go systems often are one-pass, absolute assemblers, but can just as well be two-pass and/or relocatable assemblers.
Where they are possible, load-and-go systems are generally significantly faster than non-load-and-go systems, since they save on I/O.
To demonstrate the techniques which have been discussed in this Chapter, we present here the actual code for a one-pass absolute assembler for MIXAL. The assembler accepts a MIXAL program from the card reader. It produces a listing on the line printer, and object code similar to that accepted by the absolute loader of Section 7.1 (with modifications for fix-ups).
The assembler is presented from the bottom up. That is, the simpler routines, which do not call other routines, are written first. Then we write routines which may call these routines, and so forth until the main program is written. This order of writing the assembler is possible mainly because the discussion in Section 8.2 has shown which routines we need for the assembler and how they fit together.
Each routine is written to be an independent function, as much as possible. Registers should be saved and restored by each routine as needed, with the exception of registers I5 and I6. Register I6 is used as the location counter of the assembly program. Register I5 is a column indicator for the lexical scan portion of the assembler.
Since the loader output is being written to tape, but is produced one word at a time by the assembler, several routines are needed to handle the tape output. The first two routines TAPEOUT and FINISHBUF are standard blocking routines such as discussed in Chapter 5. TAPEOUT accepts as a parameter one word, in the A register. These words are stored into a buffer of 100 words (one physical record) until the buffer is full. When the buffer is full, TAPEOUT calls FINISHBUF, which simply outputs the current buffer and resets the buffer pointers to allow double buffering. FINISHBUF can also be called to empty the last, partially filled buffer before the assembler halts.
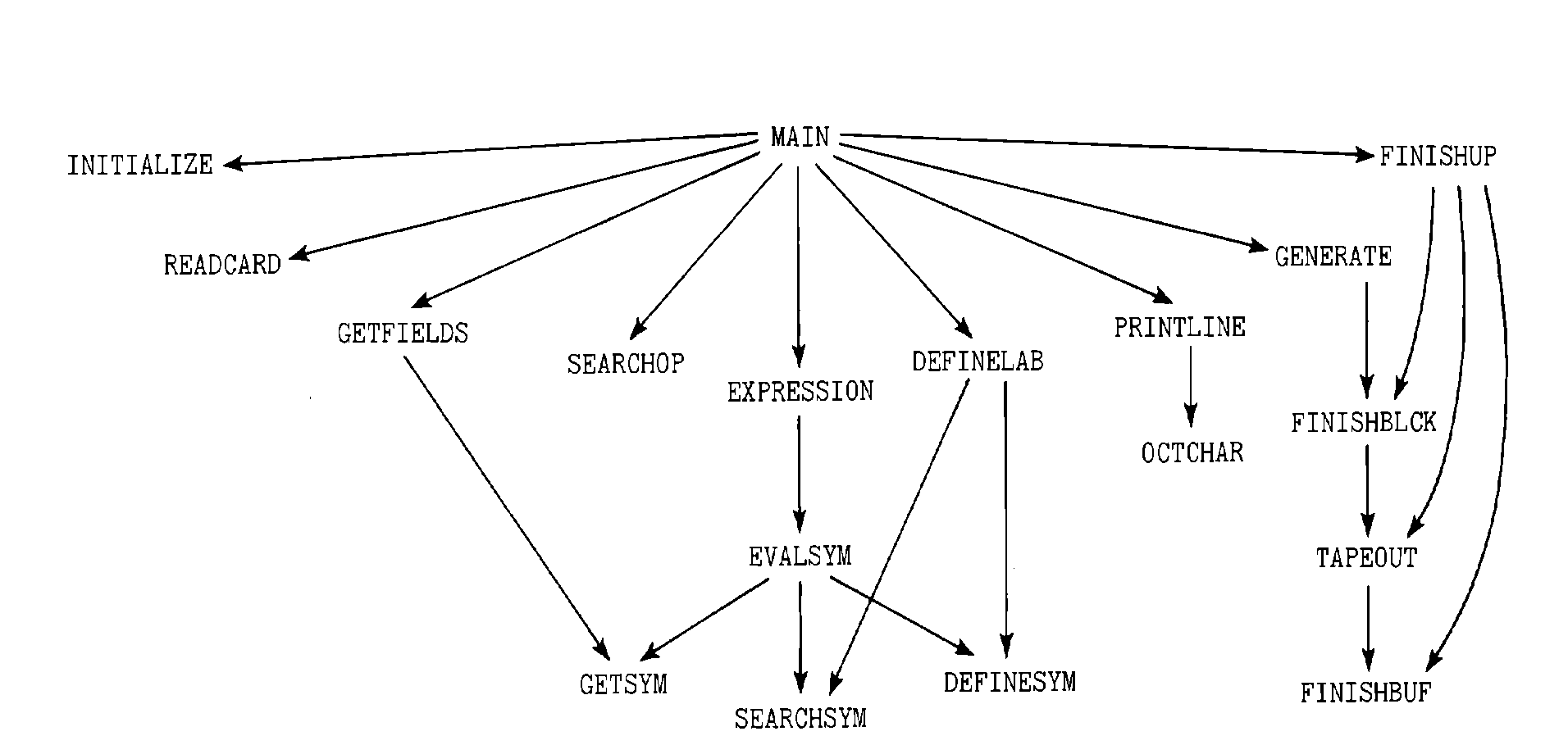 FIGURE 8.4 The subroutine structure of the example MIXAL
assembler. Each name is the name of a subroutine, and an arrow
from one subroutine to another indicates that one subroutine may
call the other in the course of its program. For example
EXPRESSION may call EVALSYM, Which may
call GETSYM, SEARCHSYM, and DEFINESYM.
FIGURE 8.4 The subroutine structure of the example MIXAL
assembler. Each name is the name of a subroutine, and an arrow
from one subroutine to another indicates that one subroutine may
call the other in the course of its program. For example
EXPRESSION may call EVALSYM, Which may
call GETSYM, SEARCHSYM, and DEFINESYM.
Variables for these routines would include the two buffers (BUF1 and BUF2), pointers to these two buffers for double buffering, and a counter of the number of words in the buffer.
The TAPEOUT routine is called mainly by the routines which create the loader output. These routines are mainly concerned with formatting the output from the assembler. The loader output is a series of logical records, as described in Chapter 7. For a one-pass absolute loader, we need three types of loader records: (a) words to be stored in memory, (b) chain addresses for forward reference fix-up, and (c) the start address of the assembled program. Each block is identified by a header word of the format shown in Figure 8.5.
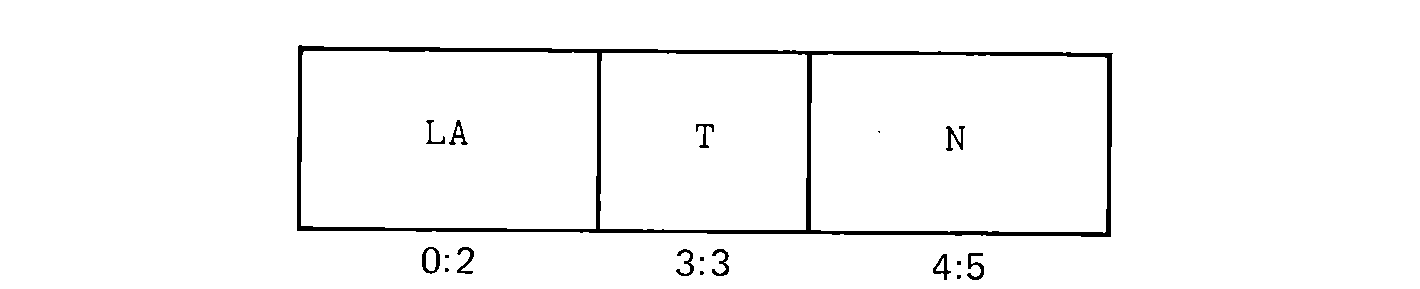 FIGURE 8.5 The format of the header word for a loader record.
FIGURE 8.5 The format of the header word for a loader record.
Byte 3 (T) is a type byte which is used to indicate the type of information in N (bytes 4:5) and LA (bytes 0:2). They can have only a value of 0, 1, or 2, as follows,
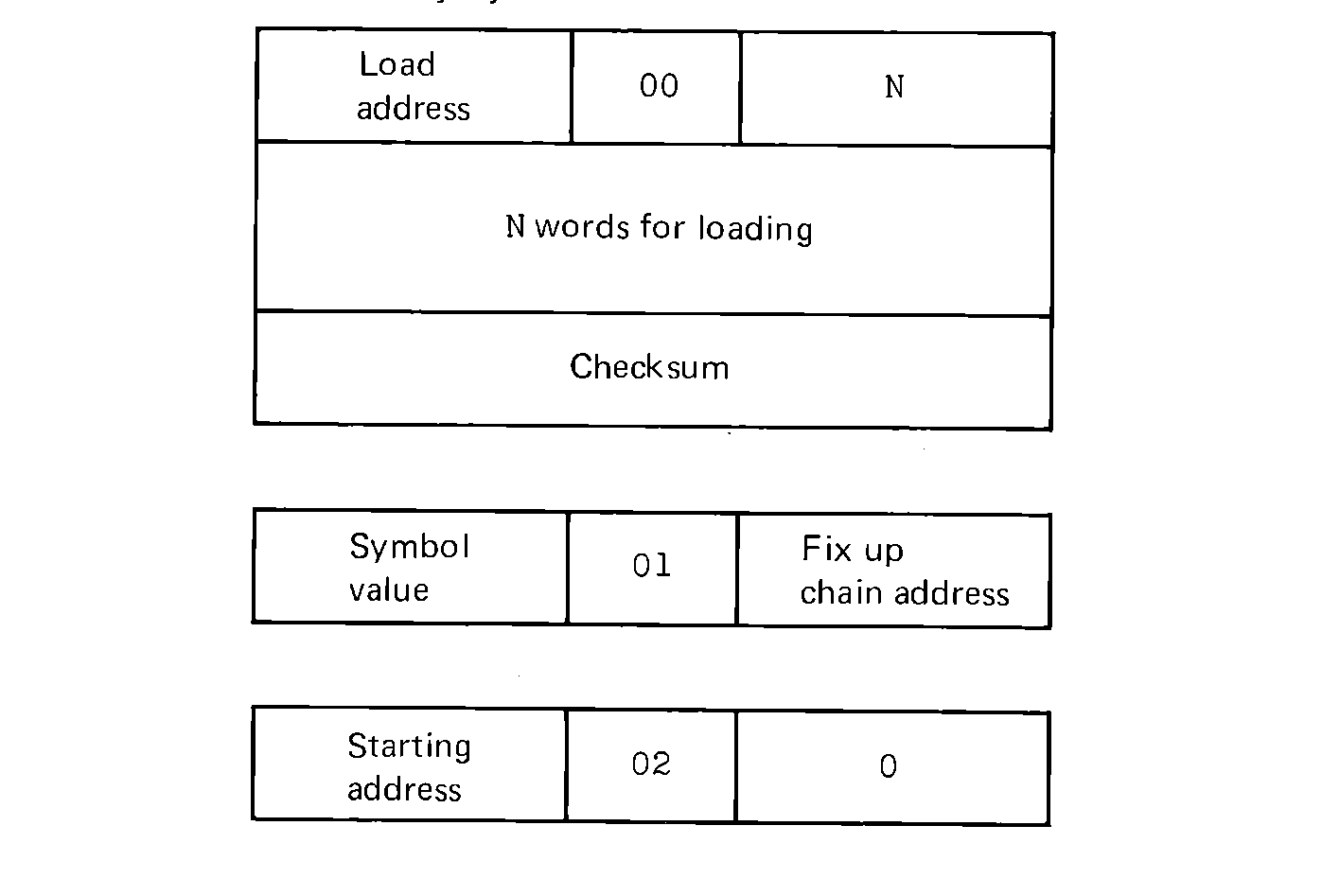 FIGURE 8.6 The three types of
loader records. The type of record is determined by byte 3:3.
FIGURE 8.6 The three types of
loader records. The type of record is determined by byte 3:3.
Most of the output to the tape will be of type 0. These words are produced by the assembler one at a time and need to be blocked into N word groups with a header in front and a checksum following. Notice that the header cannot be output until the value of N is known. So words are stored in a buffer (LDRBLOCK) until a discontinuity in load addresses occurs, or the buffer is full. Then the header and checksum are attached and the entire block written to tape by use of the routine TAPEOUT. The variables and code for this are
Two routines are used; one (GENERATE) puts the words into the loader record block (LDRBLOCK), while the other (FINISHBLCK) will empty the buffer, output it to tape, and compute the checksum.
Subroutine READCARD will read one card and unpack it into a one-character-per-word card image form. Double buffering is used.
GETSYM is the main lexical scan routine. Using index register I5 as a pointer to the card image in CARD, GETSYM packs the next symbol into SYM. SYM is 2 words, to allow up to 10 characters per symbol. A symbol is delimited by any non-alphabetic, non-numeric character. If the current character is non-alphanumeric, then SYM will be blank. The variable LETTER is used to indicate if the symbol is strictly numeric (LETTER zero) or contains an alphabetic character (LETTER non-zero). Numeric symbols are right-justified (to allow NUMing), while symbols with letters are left-justified.
GETSYM is used by GETFIELDS (among others). GETFIELDS gets the label and opcode fields of an assembly language program for later processing. This MIXAL assembler accepts only fixed-format input, and GETFIELDS reflects this. Notice that the change to a free-format assembler would require only that this one subroutine need be changed.
Both the opcode table and symbol table need search routines, and the symbol table needs an enter routine.
Each entry of the opcode table is two words. The symbolic opcode is in bytes 1:4 of the first word. Byte 5:5 is a type field. For machine instructions, word 2 has the default field and the numeric opcode in bytes 4 and 5, while word 2 is ignored for pseudo-instructions.
Each entry of the symbol table takes four words. The name of the symbol is stored in the first two words, and the value in the third word. If there were any forward references to this symbol, the fourth word contains the address of the last forward reference in bytes 4:5. Forward references are chained through this address.
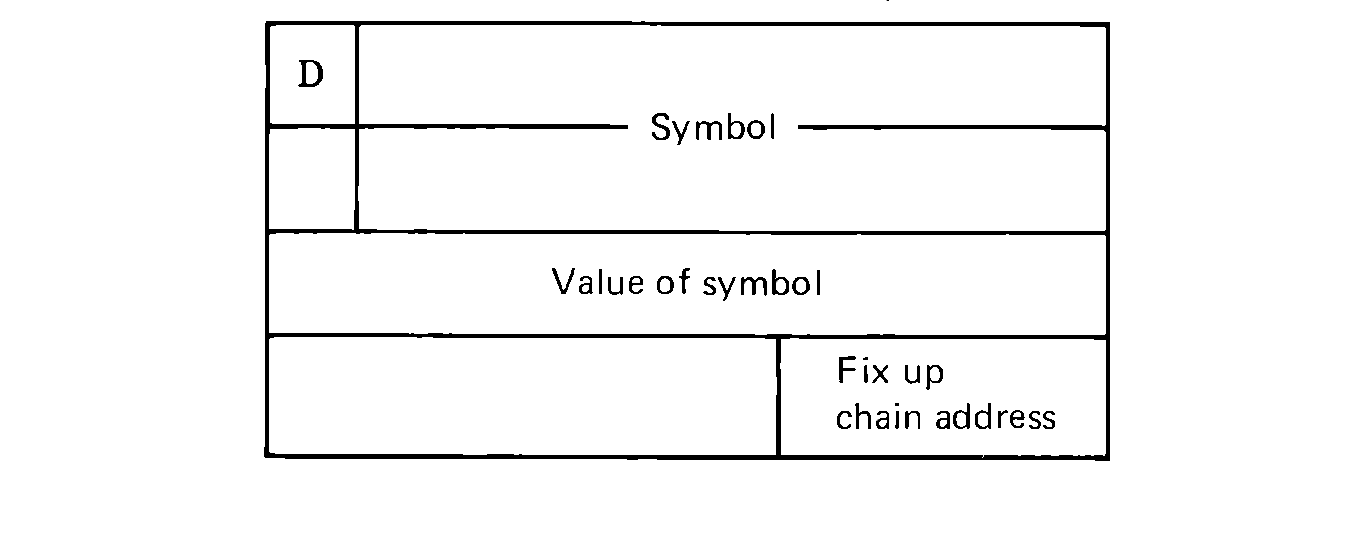 FIGURE 8.7 A symbol table entry (each entry contains the
10-character symbol, value, and a fix-up address, along with a
defined/forward reference bit, D).
FIGURE 8.7 A symbol table entry (each entry contains the
10-character symbol, value, and a fix-up address, along with a
defined/forward reference bit, D).
The sign bit of the first word (D) is used to indicate if the symbol has been defined (D = +) or undefined (D = -). A symbol is undefined only if there has been a (forward) reference to it but it has not yet appeared in the label field.
The opcode table search routine uses a binary search on the ordered opcode table. If we search with a binary search, we need the opcode table to be sorted alphabetically. If the opcode is not found, an error is flagged and a HLT instruction is assumed as the opcode. The division by two in the binary search could be replaced by a right shift by one bit if a binary MIX machine is used.
A linear search is used for the symbol table. This is not the best search possible, but it is relatively simple. Since the search is done only in this one routine, it can be changed later, if we find a linear search to be too slow. The symbol definition routine simply adds symbols to the end of the table.
Expression evaluation for the MIXAL language is relatively simple since it involves only three types of operands (symbols, numbers, and *) and evaluation of operators is strictly left to right. After checking first for a *, the EVALSYM routine uses GETSYM to get the next symbol from the input card. If the symbol has no letters (LETTER = 0), it is numeric and is converted from character code to a numeric value by the NUM instruction. If the symbol has letters, then the symbol table is searched and the value of the symbol in the symbol table is used.
The evaluation of a symbol is actually more complicated due to forward references. Two special cases may arise in the symbol table search. First, the symbol may not be there. In this case, it must be entered into the table (using DEFINESYM). Then it can be treated like the second case, which involves symbols in the table, but not defined. These are symbols which have previously appeared as forward references. They are distinguished by a "-" sign in the sign bit of the first word of the symbol table entry. In this case, the "value" of the symbol is the previous reference address and the reference address is updated to be this instruction. Since forward references are not always allowed, the undefined nature of the symbol is noted by setting the variable UNDEFSYM to non-zero.
EVALSYM is used by EXPRESSION to evaluate the components of an expression. EXPRESSION evaluates the first component (using EVALSYM) and then examines the next character. If it is a delimiter, the evaluation stops; if it is an operator, the evaluation continues. This decision is made by the use of an array (OPERATOR) which is indexed by the character code of the next character. If the value is zero, the character is a delimiter. If it is non-zero, then the character is an operator and the value is in the range 1 to 5, to be used in a jump table for interpreting that operator. Thus, since the character code for "+" is 44, OPERATOR+44 is 1, OPERATOR+45 is 2 ("-"), OPERATOR+46 is 3 ("*"), OPERATOR+47 is 4 ("/"), and OPERATOR+54 is 5 (":"). All other values are zero.
If the character following an evaluated symbol is an operator, EVALSYM is called again and the two values are combined according to the operator. This process of finding operators, calling EVALSYM to evaluate the symbol, and combining its value with the previously computed value, continues until a delimiter is found.
Several problems must be attended to. Forward references are only allowed when NOFORWARD is zero. UNDEFSYM is used to tell when a symbol is a forward reference. Overflow must also be checked and flagged as an error. This includes expressions which exceed the range which is appropriate for their intended use. (An expression for an index or field specification can only be in the range 0 to 63.) These upper and lower bounds are passed as a parameter to EXPRESSION. The address of the lower bound is passed in register I1; the upper bound follows at 1,1.
The print routine is relatively straightforward, although lengthy. Each input statement generates an output line in the listing. The most common format is the format of a machine instruction, which is
| Location counter | Generated instruction | Card image | Card number | |
|---|---|---|---|---|
| +3516 | +3514 00 05 30 | STA ERRSAVEA | 469 |
For other types of assembly language statements, this format is not always appropriate. For the CON and ALF statements, the generated code is not normally interpreted as an instruction, so it could be better presented as a five-byte signed value. For the EQU statement, no code is generated, and no location counter can thus be meaningfully associated with the statement, but the operand expression should be printed. The ORIG and END statements likewise do not generate code, but their operand expressions, which are addresses (not five-byte values) should be printed. Thus, there are several different formats for output, depending upon the type of the opcode. These are encoded in the PRTFMT table.
The PRINTLINE routine formats the output line in LINE according to the entry in PRTFMT determined by OPTYPE. LINE is then packed into PRTBUF and printed. By positioning the CARD array in the LINE array, the copying from CARD to LINE is not needed for the card image. Since the location counter may have been changed by the time that the line is formatted and printed, a separate variable, PRINTLOC, is used to store the location to be printed on the output line.
On a binary machine, it is most useful to print the output in octal, not decimal. Since the CHAR instruction converts from numeric into decimal character code, a separate routine, OCTCHAR, is used to convert into octal character code. Notice that by simply changing the divide by 8 to a divide by 10, decimal output can be generated.
Any system program must check its input carefully for possible errors, and an assembler has many opportunities for errors. Thus, errors must be checked for continuously, throughout the program.
When an error is detected, it should be signalled to the programmer somehow. For this assembler, we have elected to place flags in the first five characters to indicate any errors. If the first five characters of an output line are blank, no errors were found. If errors are found, the type of error can be identified by the character in the first five columns.
| M | Multiply-defined label. This label has been previously defined. | |
| L | Bad symbol or label. A symbol exceeds ten characters in length or the label is numeric. | |
| U | Undefined opcode. The symbolic opcode in the opcode field cannot be found in the opcode table. | |
| F | Illegal forward reference. A forward reference occurs in an expression or where it is not allowed (EQU, CON, ORIG or END, or in I or F field). | |
| O | Expression overflow. The expression evaluation resulted in a value which exceeded one MIX word, or exceeded the allowable range of the expression. | |
| S | Illegal syntax. The assembly language statement does not have correct syntax; it is not of the correct form. |
One additional routine which is useful is DEFINELAB. This routine uses DEFINESYM to define a label for an assembly language statement. It does not simply call DEFINESYM, however, but must first call SEARCHSYM to check for multiply-defined symbols, or symbols which have been forward referenced. The label is taken out of the variable LABEL, where it was put by GETFIELDS. The value of the label is in the A register.
With these subroutines to perform most of the processing, the main assembler code is now quite simple. The main loop is
Each opcode type has its own section of code to process each assembly language statement. For a machine opcode, this involves first defining the label (JMP DEFINELAB). Then the address expression is evaluated (JMP EXPRESSION) and saved in the 0:2 field of the word to be generated (VALUE). If the next character is a comma, an index field is evaluated; if the next character is a left parenthesis, a field specification is evaluated. Finally, the word is generated.
EQU statements are even simpler. The expression is evaluated, and the label defined to have this value.
ORIG statements are almost as simple as EQUs.
ALF statements are processed by simply picking up the five characters in columns 17 through 21 and packing them into VALUE.
The CON statement is perhaps the most complicated of the pseudo-instructions. It consists of evaluating the first expression, and checking for a field specification. If a field is given, the value is stored in that field. This repeats until no more expressions are found. The major complexity in the code comes from the necessity of checking that the field specification given is valid.
The last pseudo-instruction processed will be an END statement. First, any label is defined. Then the starting address is evaluated and an end-of-assembly flag is set.
With most of the assembler written, we can easily see what needs to be initialized. The first card input should be started, the loader tape should be rewound, and the location counter set to zero. All other variables were initialized by CON statements when they were declared.
Termination is more complicated. First, any unfinished loader block should be finished. Then the symbol table needs to be searched. Any undefined symbols are defined, and fix-up codes are output to the loader tape for symbols which were forward referenced. Finally, the start address is output and the last tape buffer written to tape.
The MIXAL assembler which we have presented in this chapter is a relatively simple one, despite its length. A number of improvements can be made. However, the basic structure of the assembler is such that most improvements can be made by only local modifications to a few subroutines. The entire assembler will not need to be rewritten.
These are just a few of the changes which can be, or should be made. One of the major evaluation criteria is the ability of a programmer, other than its author, to understand a program, and be able to correctly modify it.
Another evaluation criteria is performance. This can be measured in terms of either memory size or speed. For a 4000-word MIX memory, the assembler occupies about 1600 words for its code and opcode table. This leaves over half of memory for the symbol table, allowing the symbol table to hold a maximum of about 600 symbols. Reducing the size of a symbol table entry to 3 words would increase this to 800 symbols.
Since card input, listing output, and tape output are all double buffered, and overlap most of the computation, the speed of the assembler is bounded mainly by the speed of the I/O devices. The assembler took 80.9 seconds to assemble itself (1579 cards) on a 1-microsecond-per-time-unit MIX computer, with a 1200-card-per-minute card reader, and a 1200-line-per-minute line printer. Of this time, 76.1 seconds were spent waiting for I/O devices. This means that only 5.8 percent of the total execution time was needed for the assembly of the program, the remainder of the time is all I/O. Assemblers are typically very I/O bound programs.
This simple measurement means that it would be very difficult to significantly speed up the assembler. A number of minor modifications can be made to speed up the assembler (such as a better symbol table search algorithm, better use of registers, and not saving registers which are not needed). But the effect of these changes on the total processing time would be minimal at best, and hence they are probably not worth the bother.
The basic function of an assembler is to translate a program from assembly language into loader code for loading. The major data structures which assist in this translation are the opcode table, which is used to translate from symbolic opcode to numeric opcode, and the symbol table, which is used to translate programmer-defined symbols to their numeric values.
With these major data structures and subroutines to search and enter these tables, as necessary, to evaluate symbols, to evaluate expressions, to print lines, to handle errors, to buffer and block loader output, to read cards and get symbols, to initialize and terminate the assembler, the code for assembling each type of assembly language statement is relatively easy to write and understand.
The major problem for an assembler is forward references. These can be handled by either a two-pass assembler or a one-pass assembler. A one-pass assembler requires the loader to fix-up forward references.
Assemblers are a major topic for books on systems programming, and chapters on assemblers are included in Stone and Siewiorek (1975), Graham (1975), Hsiao (1975), and Donovan (1972). Gear (1974) and Ullman (1976) also discuss assemblers. The book by Barron (1969) has an extensive description of assemblers and how they work. For a look at the insides of a real assembler, try the Program Logic Manual for the assembler for the IBM 360 computers (IBM order number GY26-3716).