| Home | Up | Questions? |
The discussions of Chapters 4 and 5 have concentrated on problems related to the reachability problem, dealing mainly with problems of reachable markings. A related but quite different approach is to focus not on what markings are reachable but rather on how we reach them. The primary object of interest is then the transition and particularly the sequences of transitions which lead us from one marking to another in a Petri net.
A sequence of transitions is a string, and a set of strings
is a language. Thus, in this chapter, we concentrate on the
languages defined by Petri nets and their properties.
6.1. Motivation
Petri nets are being developed for two major reasons: (1) the description of proposed or existing systems and (2) the analysis of systems which can be modeled by a Petri net description. The analysis of a Petri net attempts to determine the properties of the net and the system which it models. One of the most important properties of a system is the set of actions which can occur. The set of all possible sequences of actions characterizes the system.
In a Petri net, actions are modeled by transitions, and the occurrence of an action is modeled by the firing of a transition. Sequences of actions are modeled by sequences of transitions. Thus the set of allowable transition sequences characterizes a Petri net and (to the degree that the Petri net correctly models a system) the modeled system.
These sequences of transitions can be of extreme importance in using Petri nets. Assume that a new system has been designed to replace an existing one. The behavior of the new system is to be identical to the old system (but the new system is cheaper, faster, easier to repair, or something). If both systems are modeled as Petri nets, then the behaviors of these two nets should be identical, and so their languages should be equal. Two Petri nets are equivalent if their languages are equal. This provides a formal basis for stating the equivalence of two systems.
A particular instance in which equivalence is important is optimization. Optimizing a Petri net involves creating a new Petri net which is equivalent (languages are equal) but for which the new net is “better” than the old one (for some definition of better). For example, if a Petri net is to be directly implemented in hardware, then a Petri net with fewer places, transitions, and arcs would be less expensive to build, since it has fewer components. Thus one optimization problem might be to reduce | P | + | T | without changing the behavior of the net.
For purposes of optimization, a set of language-preserving transformations might be useful. If a transformation applied to a Petri net produces a new Petri net with the same language, then it is language preserving. An optimal Petri net can be produced by applying language-preserving transformations to a nonoptimal Petri net. Practical use of a Petri-net-based system for modeling and analysis would require a collection of language-preserving transformations.
Petri net languages can also be useful for analysis of Petri nets. Techniques have been developed in Chapter 4 for determining specific properties of Petri nets, such as safeness, boundedness, conservation, liveness, reachability, and coverability. Although these are important (and difficult) properties to establish, they are not the only properties for which a Petri net might be analyzed. It may be necessary to establish the correctness of a modeled system by showing that system-specific properties are satisfied. Thus, either new techniques must be developed for each new property, or a general analysis technique for Petri nets is needed.
A large class of questions can be posed in terms of the sequences of actions which are possible in the system. If we define the set of possible sequences of actions as the language of the system, then we can analyze the system by analyzing the language of the system. Now problems may be answered by considering the emptiness question (Will any sequence get me from here to there?) or the membership question (Is a sequence of this form possible?). This may provide us with a general technique for analyzing arbitrary systems for system-specific properties. Riddle [1972] has investigated analysis based on the language of the modeled system.
Another use of Petri net languages would be in the specification and automatic synthesis of Petri nets. If the behavior which is desired can be specified as a language, then it may be possible to automatically synthesize a Petri net whose language is the specified language. This Petri net can be used as a controller, guaranteeing that all and only the sequences specified are possible. Path expressions [Lauer and Campbell 1974] have been developed to define allowable sequences of actions. Techniques have been developed for automatically creating a Petri net from a path expression.
Another motivation for the study of Petri net languages
comes from a desire to determine decidability results for
Petri nets. The decidability of many properties of Petri
nets is unknown. The decidability of a few basic questions
for Petri nets, such as reachability, is the object of much
current research. One area in which decidability questions
have been considered is formal language theory. By
consideration of the languages of Petri nets, the concepts
and techniques of formal language theory may be brought to
bear on the problems of Petri nets. This may produce new
results concerning Petri nets and their decidability
questions. It is also possible to use Petri net methods to
obtain new useful results about formal languages.
6.2. Related Formal Language Theory Concepts
The Petri net language theory which has developed so far is similar to development of other parts of formal language theory. Several books present the classical theory of formal languages [Hopcroft and Ullman 1969; Salomaa 1973; Ginsburg 1966]. Many of the basic concepts of Petri net language theory have been borrowed from the classical theory of formal languages.
An alphabet is a finite set of symbols. A string is any sequence of finite length of symbols from the alphabet. The null or empty string λ is the string of no symbols and zero length. If Σ is an alphabet, then Σ* is the set of all strings of symbols from Σ, including the empty string. Σ+ is the set of all nonempty strings over an alphabet Σ . Σ* = Σ+ ∪ { λ } .
A language is a set of strings over an alphabet. Languages may in general be infinite; thus representing the language is a problem. Two approaches have been developed for representing languages. One approach is to define a machine which when executed generates a string from the language, and all strings of the language are generated by some execution. Alternatively, a grammar may be defined which specifies how to generate a string of a language by successively applying the productions of the grammar.
Restrictions on the forms of the machines or grammars which generate the languages define classes of languages. The traditional classes of languages are regular, context-free, context-sensitive, and type-0 languages, corresponding to finite state machines, pushdown automata, linear bounded automata, and Turing machines. Each of these classes of languages is generated by the appropriate class of automata. This provides an excellent means of linking Petri net theory to formal language theory: We define the class of Petri net languages as the class of languages generated by Petri nets. The details of the definition should be similar to the details for any of the other classes of languages.
As an example, let us consider finite state machines and
regular expressions. A finite state machine C is a
five-tuple ( Q, δ, Σ, s, F ), where Q is a
finite set of states, Σ is an alphabet of symbols,
δ: Q ⨯ Σ → Q is a next state
function, s ∈ Q is the start state, and
F ⊆ Q is a finite set of final states.
The next state function δ is extended to a function
from Q ⨯ Σ* to Q in the natural way. The
language L ( C ) generated by the finite state machine is the
set of strings over Σ defined by
| L(C) | = | { α ∈ Σ* | δ(s, α) ∈ F } |
With each finite state machine is associated a language, and
the class of all languages which can be generated by finite
state machines is called the class of regular languages.
The language of a finite state machine is a characterizing
feature of the machine. If two finite state machines have
the same language, they are equivalent.
6.3. Definitions of Petri Net Languages
The same basic concepts used to produce a regular language
from a finite state machine can be applied to Petri nets to
produce a theory of Petri net languages. In addition to the
Petri net structure defined by the sets of places and
transitions (which correspond roughly to the state set and
next-state function of the finite state machine), it is
necessary to define an initial state, an alphabet, and a set
of final states. The specification of these features for a
Petri net can result in different classes of Petri nets. We
consider each of these in turn.
6.3.1. Initial State
The initial state of a Petri net can be defined in several ways. The most common definition is to allow an arbitrary marking μ to be specified as an initial state. However, this definition can be modified in several ways. One convenient limitation is to restrict the initial state to a marking with one token in a start place and zero tokens elsewhere [Peterson 1976]. Another more general definition allows a set of initial markings rather than simply one marking.
These three definitions are essentially the same. Certainly the start place definition is a special case of the initial marking definition, which is a special case of the set of initial markings definition. However, if a set of initial markings M = { μ1, μ2, …, μk } is needed with a start place definition, we can simply augment the Petri net with an extra place p0 and a set of transitions { t1′, …, tk′ } . Transition tj′ would input a token from p0 and would output marking μj. Thus the behavior of the augmented net would be identical to a Petri net with a set of initial markings, except that each transition sequence would be preceded with tj′ if marking μj were used to start the execution.
We see then that these three definitions of start states for
a Petri net are essentially equivalent. Out of a sense of
tradition, we define a Petri net language as starting from a
single arbitrary marking μ .
6.3.2. Labeling of Petri Nets
Labeling Petri nets is another situation where several definitions can be used. We must define both what the alphabet Σ of a Petri net should be and how it is to be associated with the Petri net. We have indicated that the symbols are associated with the transitions, so that a sequence of transition firings generates a string of symbols for the language. The association of symbols to transitions is made by a labeling function, σ: T → Σ . Variations in language definition may result from various restrictions placed on the labeling function.
A free-labeled Petri net is a labeled Petri net where all transitions are labeled distinctly [i.e., if σ ( ti ) = σ ( tj ), then ti = tj ]. The class of free Petri net languages is a subset of the class of Petri net languages with a more general labeling function which does not require distinct labels. An even more general labeling function has been considered which allows null labeled transitions, σ ( tj ) = λ . These λ -labeled transitions do not appear in a sentence of a Petri net language, and their occurrence in an execution of a Petri net thus goes unrecorded. These three classes of labeling functions (free, λ -free, and with λ -transitions) define three variations of Petri net languages.
Without further investigation, it is not obvious which of
these three labeling definitions is most reasonable.
Perhaps each of the three is the most useful labeling
function for some application. Thus, we need to consider
the languages resulting from each possible definition of the
labeling function.
6.3.3. Final States of a Petri Net
The definition of final states for a Petri net has a major effect upon the language of a Petri net. Four major different definitions of the final state set of a Petri net have been suggested. Each of these may produce different Petri net languages.
One definition is derived from the analogous concept for finite state machines. It defines the set of final states F as a finite set of final markings. For this definition we define the class of L-type Petri net languages.
The class of L-type Petri net languages is rich and powerful, but it has been suggested that the requirement for a sentence to result in exactly a final state in order to be generated is contrary to the basic philosophy of a Petri net. This comment is based on the observation that if δ ( μ, tj ) is defined for a marking μ and a transition tj, then δ ( μ′, tj ) is defined for any μ′ ≥ μ . From this comment we define a new class of languages, the class of G-type Petri net languages, by the following.
A third class of Petri net languages is the class of T-type Petri net languages. These are defined by identifying the set of final states used in the definition of L-type languages with the (not necessarily finite) set of terminal states. A state μt is terminal if σ ( μt, tj ) is undefined for all tj ∈ T. Thus the class of T-type Petri net languages is as follows.
Still a fourth class of languages is the class of P-type Petri net languages whose final state set includes all reachable states. These languages are prefix languages since if α ∈ Σ* is an element of a P-type language, then for all prefixes β of α ( α = β x for some x ∈ Σ* ) β is an element of that same language.
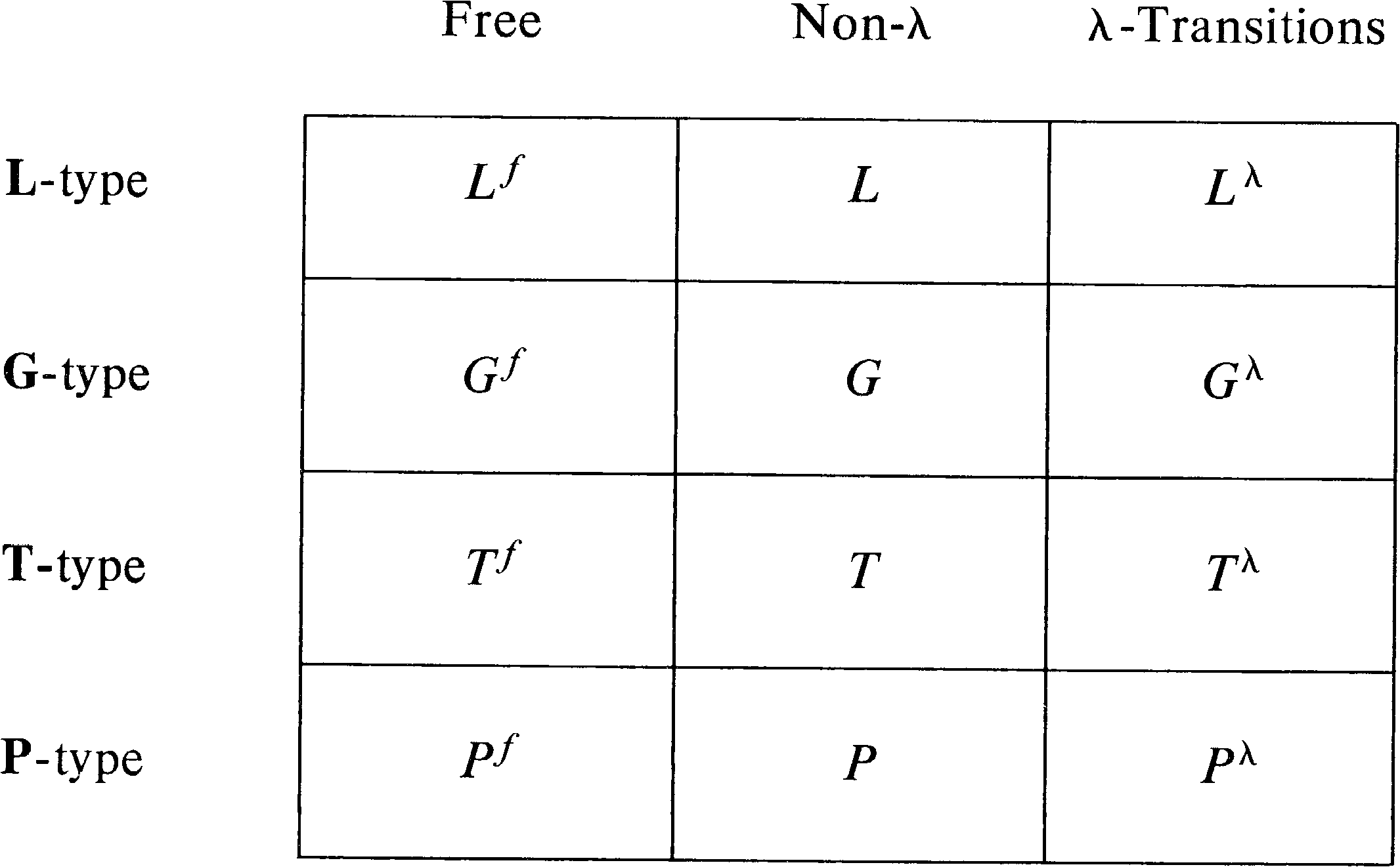
In addition to the four classes of languages based on
different specifications of the final state set, we have the
previously mentioned variations due to the labeling
function. Figure 6.1 lists the 12 classes of languages
which result from the cross product of the four types of
final state specification and the three types of labeling
functions. Each cell of Figure 6.1 lists the notation which
is used to denote each class of Petri net language.
To specify a particular Petri net language, four quantities must be defined: the Petri net structure, C = (P, T, I, O) ; the labeling function, σ: T → Σ ; the initial marking, μ: P → N, and the set of final markings, F (for L- and G-type languages). We define γ = (C, σ, μ, F) to be a labeled Petri net with Petri net structure C, labeling σ, initial marking μ, and final state set F. For a given labeled Petri net γ, 12 languages can be defined: L ( γ ), G ( γ ), T ( γ ), P ( γ ), Lf ( γ ), Gf ( γ ), Tf ( γ ), Pf ( γ ), Lλ ( γ ), Gλ ( γ ), Tλ ( γ ), Pλ ( γ ) .
The different definitions of Petri net languages can
associate different languages with a given Petri net.
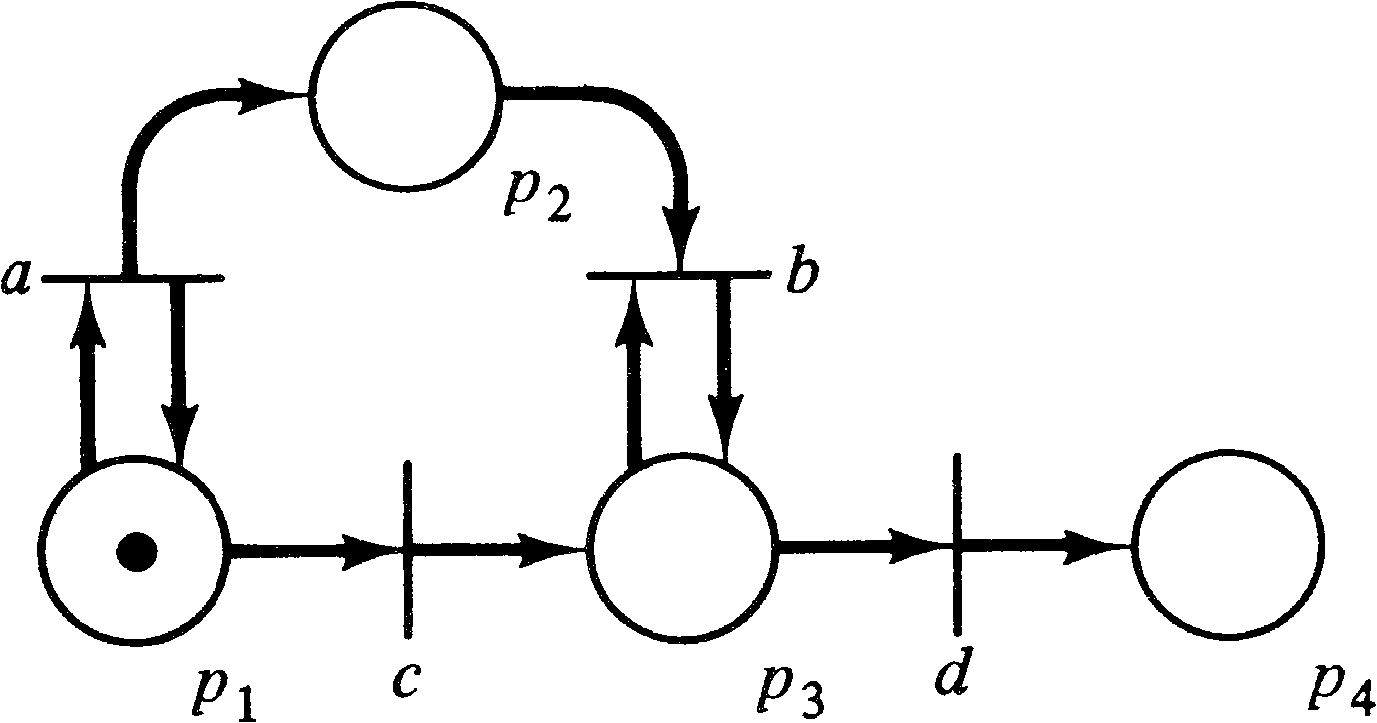
Consider, for example, the Petri net of Figure 6.2. The
initial marking of (1, 0, 0, 0) is given on the net, and
each transition tj is labeled by
σ ( tj ) . If we define
F = { (0, 0, 1, 0) } (one token
in place p3 ), the L-type language
is { an c bn | n ≥ 0 },
the G-type language is
{ am c bn | m ≥ n ≥ 0 },
the T-type language is
{ am c bn d | m ≥ n ≥ 0 },
and the P-type language is
{ am | m ≥ 0 } ∪ { am c bn | m ≥ n ≥ 0 } ∪ { am c bn d |m ≥ n ≥ 0 } .
For this example, all four types of languages are different.
The labeling function given is a free labeling, but by
using different labeling functions, other languages can
also be produced.
Despite the differences in definitions, the classes of Petri
net languages are closely related. For instance, the set of
free labelings is a subset of the set of non- λ
labelings, which is a subset of the set of
λ -labelings. Thus,
| Lf | ⊆ L ⊆ Lλ |
| Gf ⊆ G ⊆ Gλ | |
| Tf ⊆ T ⊆ Tλ | |
| Pf ⊆ P ⊆ Pλ |
Also, every P-type language is a G-type language where
F = { (0, 0, …, 0) } . Thus,
| Pf | ⊆ Gf |
| P ⊆ G | |
| Pλ ⊆ Gλ |
We can also show that each language of type G or Gλ is also a language of type L or Lλ, respectively. Let G be a G-type language for a Petri net structure (P, T, I, O), initial marking μ, and final set F. Construct a new labeled Petri net with the same places but with additional transitions as defined by the following:
For each tj ∈ T, let Bj be the set of all proper subbags of O ( tj ) . Each subbag in Bj is used to define a new transition with the same label and inputs as tj but with the subbag as output. These new transitions are added to the previous set of transitions.
For example, if we consider the transition labeled a in the
Petri net of Figure 6.2, its input bag
is { p1 }, and
its output bag is { p1, p2 } . The subbags
of { p1, p2 } are { p1 }, { p2 }, and { } ( = ∅ ). This transition would
result in three new transitions being added to the net. All
of these new transitions would be labeled a and have input
bag { p1 }, but the output bags would be the three
subbags listed above (one transition for each subbag). New
transitions would also be added for the transitions labeled
b, c, and d, which would have the same
inputs but null outputs (since the current outputs are
singleton bags and hence the only subbag is ∅ ).
This new net is shown in Figure 6.3.
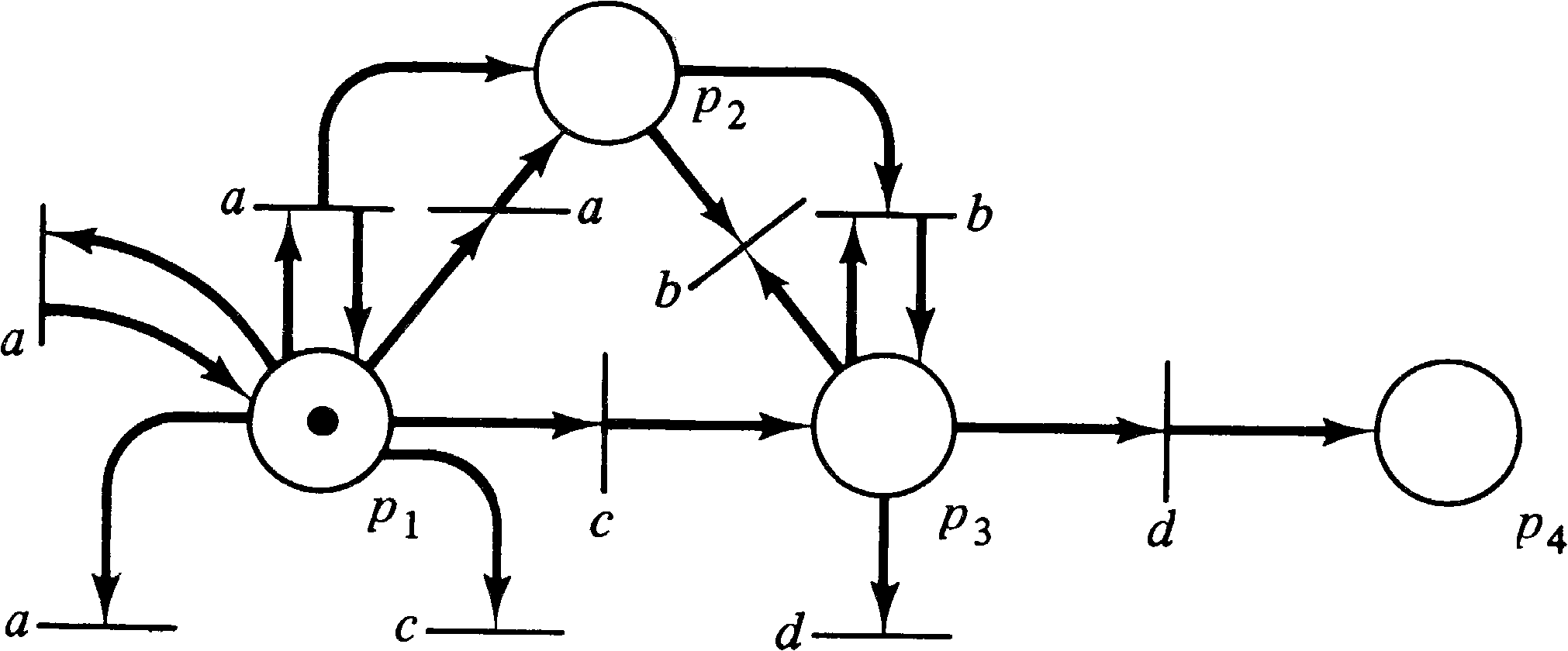
This new net has been modified in such a way that the
“extra” tokens which exceed a final state in F need not be
produced, if one selects the appropriate new transition which
has fewer outputs. Thus the L-type language of the new net
is the same as the G-type language of the old net.
| G | ⊆ L |
| Gλ ⊆ Lλ |
The above construction can also be modified slightly to show that a generalization of the definition of L-type languages (to permit incompletely specified final markings) does not change the classes L and Lλ. Let a final marking for a Petri net with n places be an n -vector over N ∪ { ω } . If a component of a final marking is ω, this means we do not care what the value of that component is in a final state. A state s is a final state if there exists a final marking f such that for all i, 1 ≤ i ≤ n, if fi ≠ ω, then si = fi. This is obviously a more general definition than the definition of L-type languages given earlier.
Now consider a language which is defined by a Petri net and an incompletely specified final marking, f. Let τ be the set of all places for which fi = ω . For each transition tj ∈ T for which O ( tj ) ∩ τ ≠ ∅, let ρj = O ( tj ) ∩ τ and ψj = O ( tj ) − ρj. The bag ρj is all places whose markings are don't-cares, while the bag ψj is all places whose markings must be exactly as specified in the final marking f. We add new transitions to the net whose label and input bag are the same as the label and input bag for tj but whose output bag is ψj + ξ, where ξ ranges over all subbags of ρj. This construction does not in any way modify the behavior of those places which are not in τ but allows those places which are don't-cares to have any number of tokens less than or equal to the number of tokens which would have appeared in the original net. Thus, for each sentence in the generalized language of the original net, it is possible to pick appropriate transitions to fire so that when the net reaches a state s such that si = fi for fi ≠ ω, then si = 0 for fi = ω . Thus the L-type language for the constructed Petri net with a final marking f′ (where all ω in the incompletely specified marking f have been replaced by 0) is the same as the generalized language of the original net (as defined by the incompletely specified final marking f ).
For a language defined by a set of incompletely specified final markings (as opposed to only one such marking as just discussed), we use the fact that L (and Lλ ) languages are closed under union (see Section 6.5.2) to show that the language is still an L (or Lλ ) language.
With the introduction of incompletely specified final markings, we can show that T-type languages are also L-type languages (except possibly for free T-type languages).
A final state μ for a T-type language is such that no transition tj can fire [i.e., ≥ μ ≱ I ( tj )">] for all tj ∈ T ]. The condition which specifies a final state for a T-type language is thus exactly the opposite of the condition specifying a final state for a G-type language. (We might call the T-type languages inverse G-type languages.) It is not difficult to see that such a set of markings can be described by a finite set of incompletely specified markings (as was done in Section 5.4). For example, the condition [≥ μ ≱ (2, 0) and ≥ μ ≱ (1, 1) ] is equivalent to [ μ = (0, ω ) or μ = (1, 0) ]. A T-type language (or, more generally, an inverse G-type language) can thus be rewritten as a generalized (i.e., incompletely specified) L-type language and then as an L-type language. Thus T ⊆ L, and Tλ ⊆ Lλ.
It is known that every Lλ -type language can be generated by a Petri net in which every transition has an input place, and where the unique final marking is the zero marking, at which no transition is fireable [Hack 1975b]. If we add to every place a λ -transition with a single input and a single output of that same place (i.e., a self-loop), then the language is not changed, and the zero marking becomes the only terminal marking. Hence, Lλ ⊆ Tλ, and from our previous demonstration that Tλ ⊆ Lλ, these two classes of languages are identical, Tλ = Lλ.
Figure 6.4 represents graphically the relationships among
the classes of Petri net languages which we have just
derived. An arc between classes indicates the containment
of one class of Petri net languages within another.
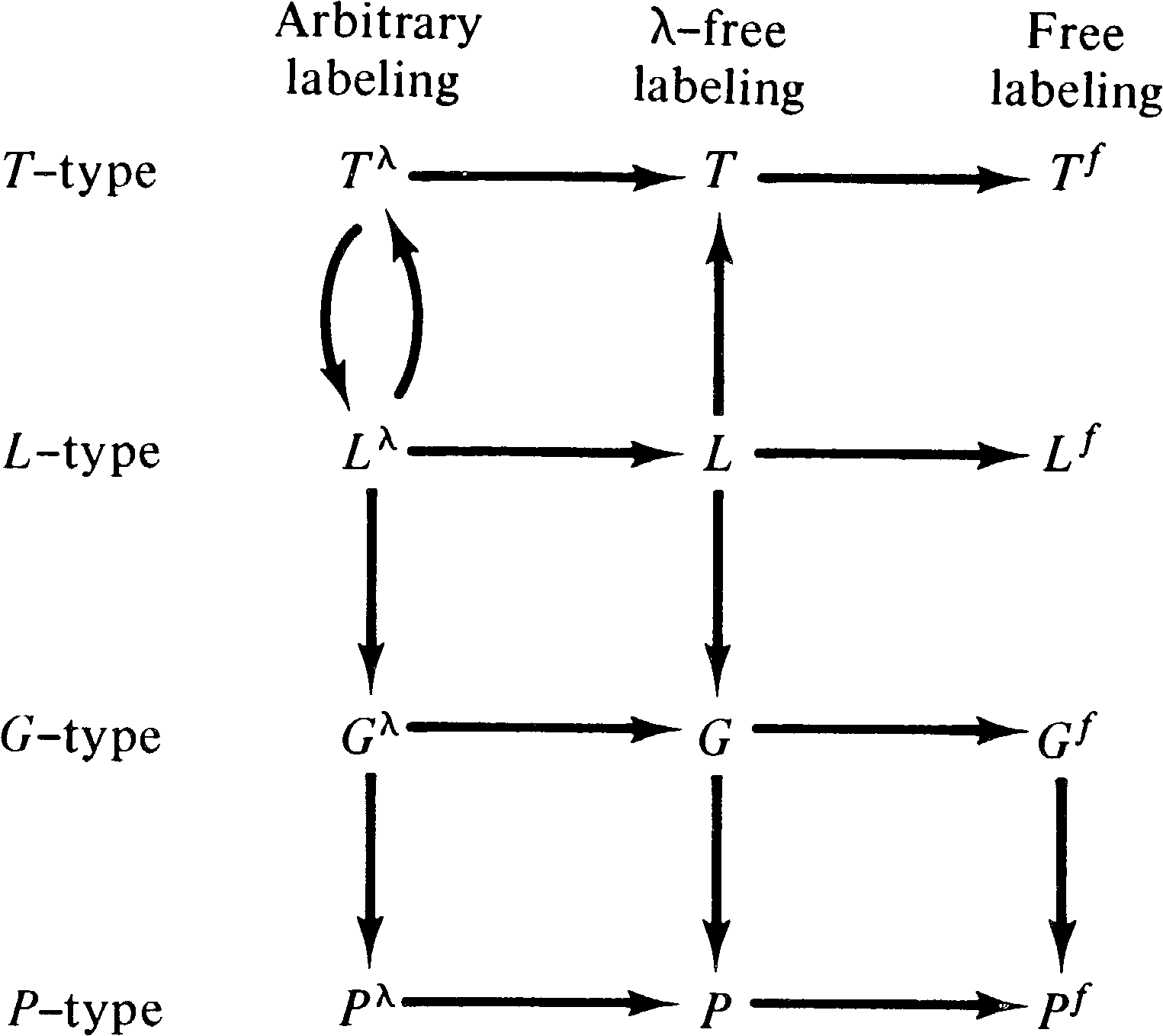
The study of Petri net languages is just beginning, and at present knowledge of the properties of these newly defined classes of languages is limited. The power of Petri nets is reflected in the variety of potentially different classes of Petri net languages which can be defined. The newness of this research is reflected by our inability to either show the complete relationships between these languages, or to argue that only a few of these classes are of importance. This results in a vast field of study, with the need to develop the properties of 12 different classes of languages.
It is obviously not possible to develop all 12 classes of languages in this volume, and so we limit ourselves here to considering only one class of Petri net languages, the L-type languages. The major reasons for this limitation are space and the fact that this language has been investigated in the literature [Peterson 1973; Hack 1975b; Peterson 1976]. Some results have also been obtained by Hack [1975b] for the prefix (P-type) languages and will be presented in our summary. The G-type and T-type languages have been defined, but no work has been done on their development. Remember also that the class of L-type languages includes the classes of T-type, G-type, and P-type languages. Thus, L-type languages are in some sense the largest class of Petri net languages and so are appropriately investigated first.
Our investigation of the properties of L-type Petri net languages will focus on two aspects. First we present closure properties of Petri nets under certain common operations (concatenation, union, concurrency, intersection, reversal, complement, indefinite concatenation, and substitution). Then we consider the relationship between Petri net languages and the classical formal languages: regular, context-free, context-sensitive, and type-0. This presentation provides an understanding of the power and limitations of (L-type) Petri net languages. It also indicates how the other classes of Petri net languages can be investigated.
Although we are interested in the entire class of L-type Petri net languages, we limit our discussion to only a limited set of standard form Petri nets. This limitation is made in order to ease the proofs and constructions; it does not limit the class of Petri net languages. For every Petri net language, there may be many Petri nets which generate that language; we choose to work only with those nets with certain properties. To show that this does not reduce the set of languages, we show that for every L-type Petri net language there exists a standard form Petri net which generates it.
First we define a standard form Petri net.
The execution of a Petri net in standard form begins with one token in the start place. The first transition which fires removes this token from the start place, and after this firing the start place is always empty. Eventually the Petri net may stop by placing one token in the final place. This token cannot be removed from the final place both because no place has an input from the final place and because all transitions are disabled. Thus the execution of a Petri net in standard form is quite simple and limited. This is of great use when compositions of Petri nets are constructed. To show that Petri nets in standard form are not less powerful than general Petri nets, we prove the following theorem.
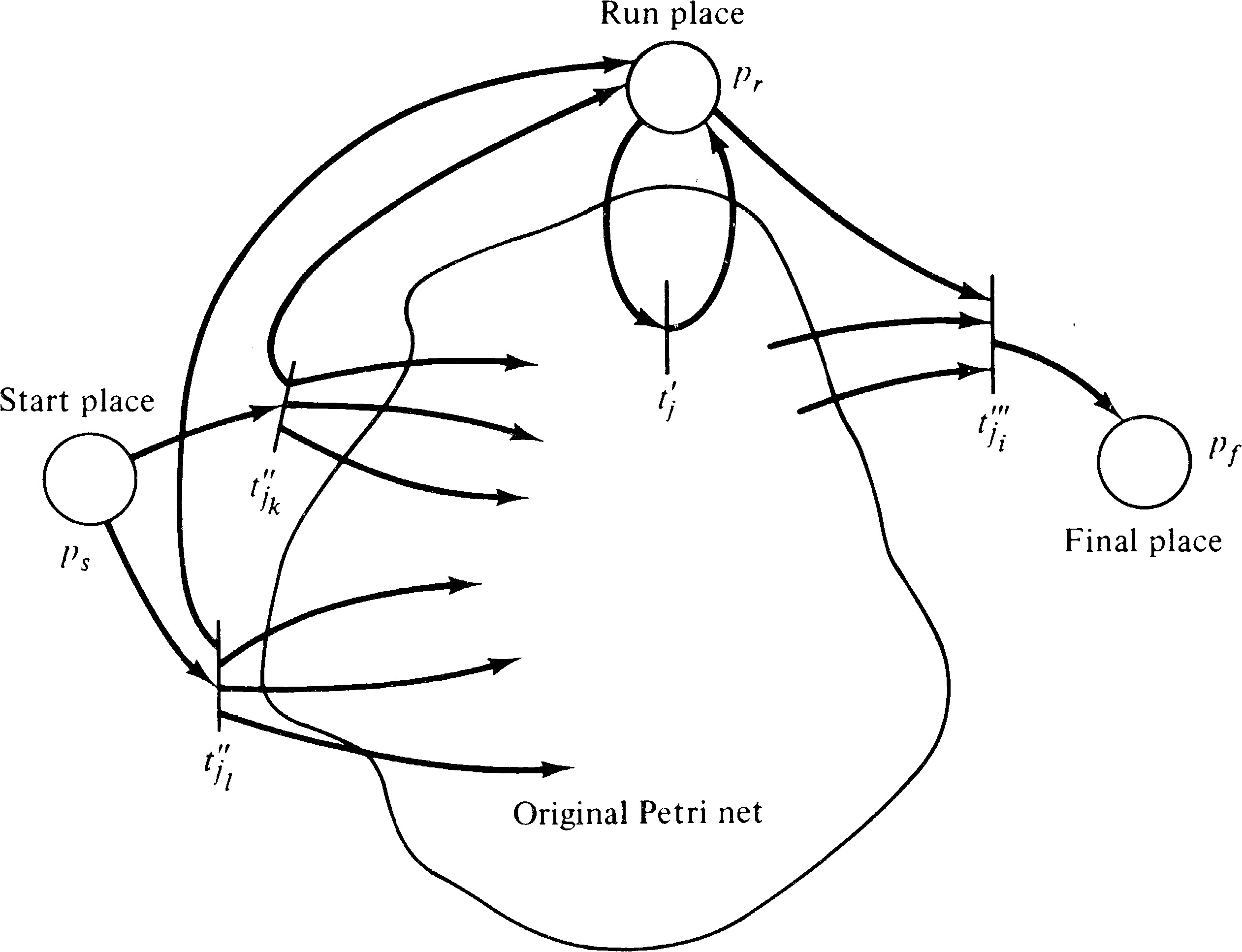
To start, we define three new places pr, pf, and ps which are not in p. Place ps is the start place, place pf is the final place, and pr is a “run” place; a token must be in pr to allow any transition in T to fire. The initial marking of C′ will have one token in ps; the final marking will consist of one token in ps [if λ ∈ L ( γ ) ] or pf [for λ ∉ L ( γ ) ].
Now we wish to be sure that every transition sequence in C leading from the initial marking to a final marking is “mimicked” in C′ . To this end we consider three types of strings in L ( γ ) . First, the empty string λ is properly handled by the definition of F′ . We can determine if λ ∈ L ( γ ) by checking if the initial marking μ is a final marking μ ∈ F. Second, for all strings of length 1 in L ( γ ), we include a special transition from ps to pf in C′ as follows: For α ∈ Σ with α ∈ L ( γ ), define tα ∈ T′, with I ( tα ) = { ps } and O ( tα ) = { pf } . The label for tα is α . We can determine if α ∈ L ( γ ) by checking all transitions tj ∈ T, with σ ( tj ) = α, to see if δ ( μ, tj ) ∈ F.
Finally, consider all strings of length greater than 1.
These strings result from a transition sequence
| tj1 tj2... tji |
| a tj1′ ⋯ tji′ b |
| a tj1′ ⋯ tji′ b |
| tj1... tji |
Unfortunately this would produce a sequence which is too long since the extra symbols corresponding to transitions a and b would exist for C′ but not for C. One solution would be a null labeling for a and b, but the L-type languages do not allow null labelings. So to solve this problem we are forced to collapse transitions a and tj1′ into one transition tj1′′ and collapse transition b and tji′ into tji′′′ . Thus for all tj ∈ T we define the following transitions in T′:
| σ′(tj′) | = | σ′(tj′′) | = | σ′(tj′′′) | = | σ(tj) |
| α | = | σ′(tj1′′ tj2′ ⋯ tji − 1′ tji′′′) |
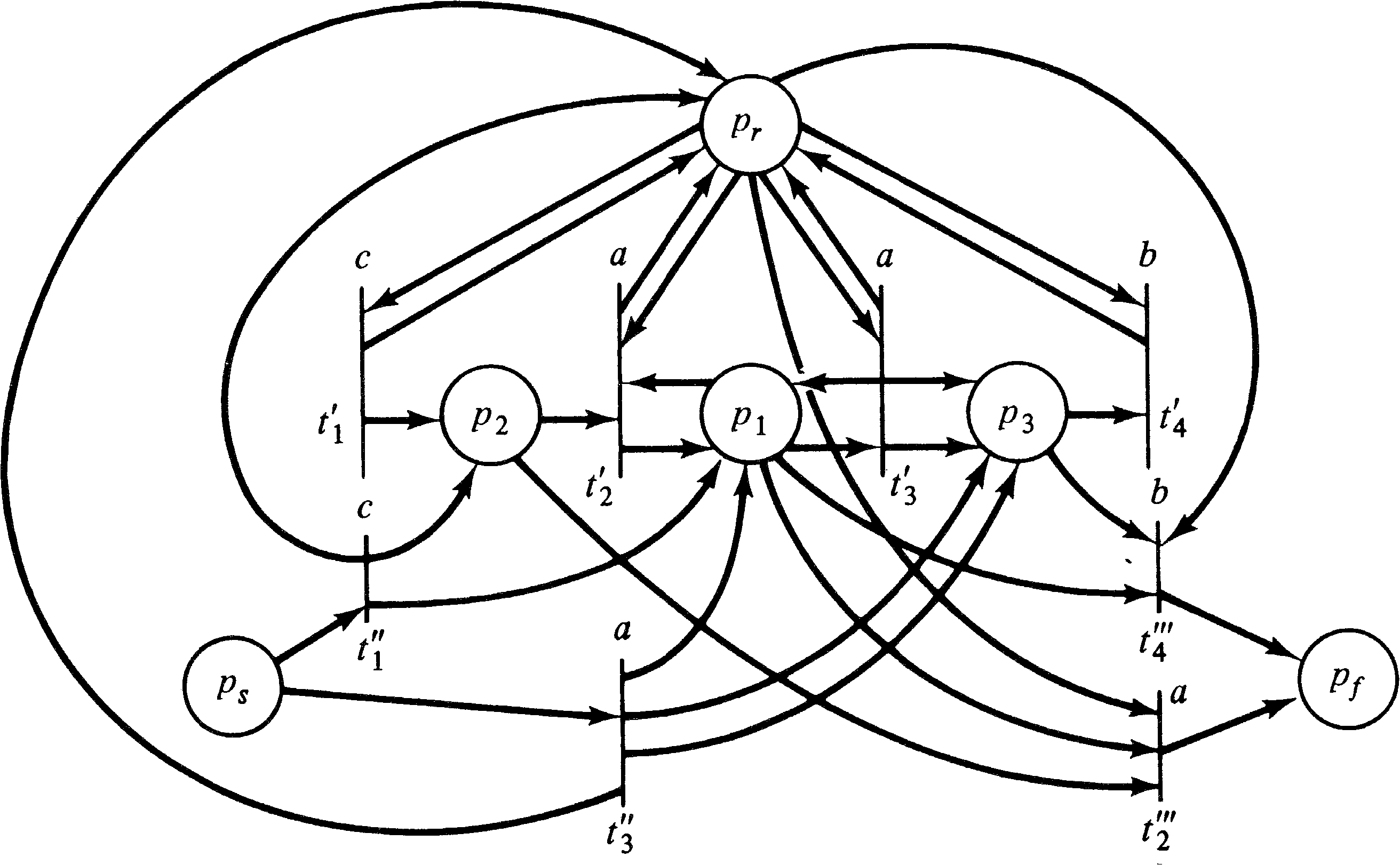
Figure 6.6 gives a simple Petri net which is not in standard
form. Applying the construction of the proof to this Petri
net produces the standard form Petri net of Figure 6.7.

We now examine the closure properties of Petri net languages under several forms of composition (union, intersection, concatenation, concurrency, and substitution) and under some operations (reversal, complement, and indefinite concatenation). The motivation for this examination is twofold. First, it increases our understanding of the properties and limits of Petri net languages as languages. Second, many of these compositions reflect how large systems are designed and constructed by the composition of smaller systems into larger systems. Thus, this investigation may help in the development of synthesis techniques.
Most of the closure properties deal with compositions of Petri net languages. For this we assume two Petri net languages L1 and L2. We know that each of these languages is generated by some Petri net in standard form. Thus, we consider the two standard form labeled Petri nets γ1 = (C1, σ1, μ1, F1 ) and γ2 = (C2, σ2, μ2, F2 ) with L1 = L ( γ1 ) and L2 = L ( γ2 ) . Since they are in standard form, γ1 has a start place ps1 ∈ P1 and γ2 has ps2 ∈ P2. Also F1 = { ps1, pf1 } or { pf1 } and F2 = { ps2, pf2 } or { pf2 } .
From these two labeled Petri nets we show how to construct a new labeled Petri net γ′ = (C′, σ′, μ′, F′ ) with language L ( γ′ ) which is the desired composition of L1 and L2. We illustrate these constructions with example Petri nets.
We begin by considering the composition of two Petri net
languages by concatenation, union, intersection, and
concurrency. Then we consider the reversal and complement
of a Petri net language and, finally, substitution.
6.5.1. Concatenation
Many systems are composed of two sequential subsystems.
Each of the subsystems may separately be expressed as a
Petri net with its own Petri net language. When the two
systems are combined sequentially, the resulting execution
is the concatenation of an execution from the first
Petri net language with an execution from the second. The
concatenation of two languages can be formally expressed as
| L1L2 | = | { x1 x2 | x1 ∈ L1, x2 ∈ L2 } |
The formal definition of γ′ must take into
consideration the empty string and so is more complex but
can be defined as the union of γ1 and γ2
with the following extra transitions. For each transition
tj ∈ T2 with
I2( tj ) = { ps2 }, we
introduce a new transition tj′ with
I′ ( tj′ ) = { pf1 } and
O′ ( tj′ ) = O2( tj ) .
If ps1 ∈ F1,
then we also add
tj′′ with
I′ ( tj′′ ) = { ps1 }
and O′ ( tj′′ ) = O2( tj ) .
We define
σ′ ( tj′ ) = σ2( tj )
and σ′ ( tj′′ ) = σ2( tj ) .
The new final set F′ is
F1 ∪ F2
if ps2 ∈ F2;
otherwise F′ = F2.
Q.E.D.
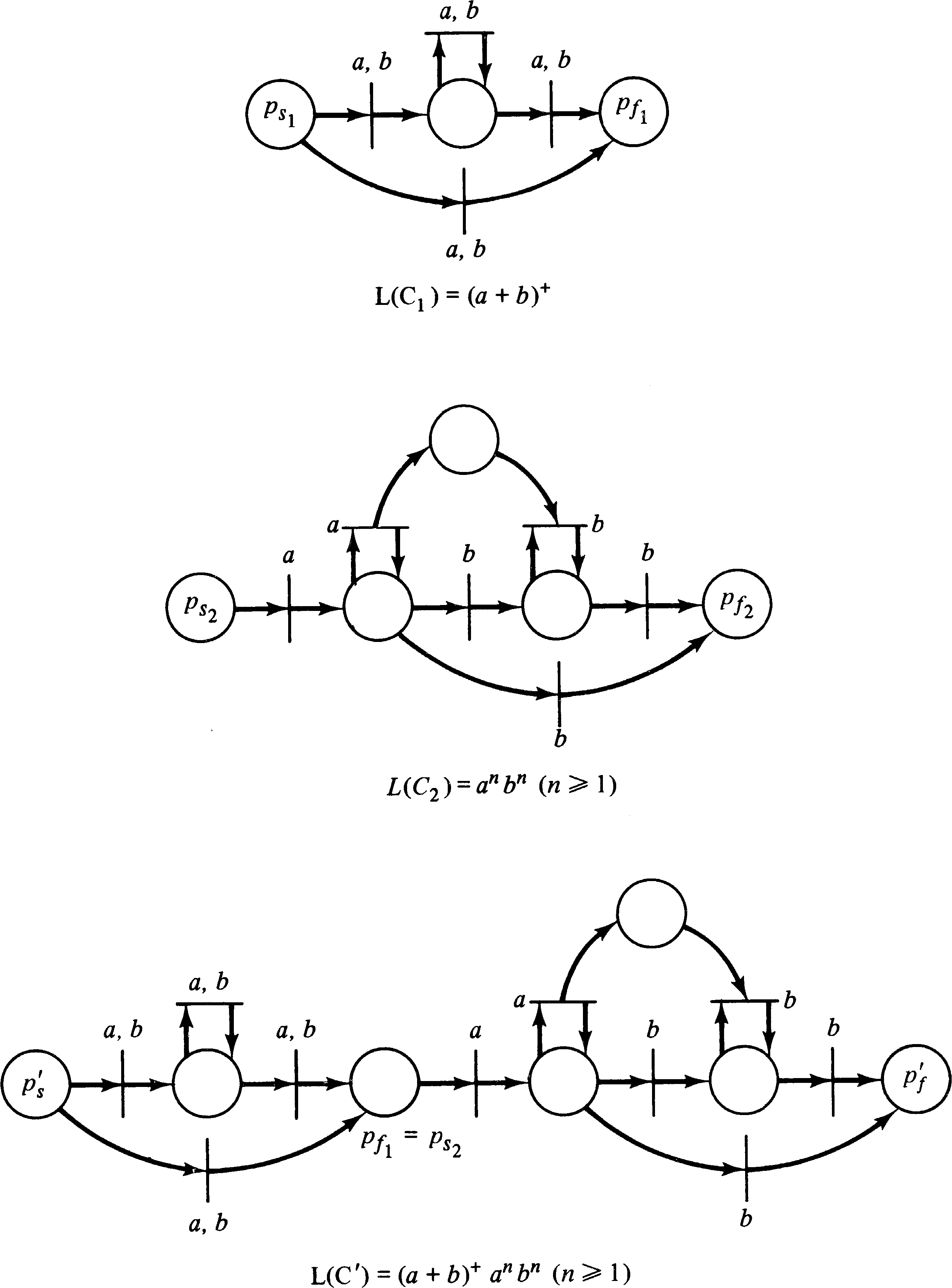
This shows that Petri net languages are closed under
concatenation. Figure 6.8 illustrates this construction for
L1 = ( a + b )+ and
L2 = an bn.
Another common method of combining systems is union.
In this composition either one, but only one, of the
subsystems will be executed. This is similar to set union
and is a common composition of languages. It can be defined
by
| L1 ∪ L2 | = | { x | x ∈ L1 or x ∈ L2 } |
Formally we define a new start place
ps′ and new transitions
tj1′ for each
tj1 ∈ T1 with
I ( tj1 ) = ps1 and
tj2′ for each
tj2 ∈ T2 with
I ( tj2 ) = ps2. We define
I′ ( tj1′ ) = ps′ and
I′ ( tj2′ ) = ps′
with O′ ( tj1′ ) = O1( tj1 ) and
O′ ( tj2′ ) = O2( tj2 ) .
The labeling function
σ′ ( tj1′ ) = σ1( tj1 )
and σ′ ( tj2 ) = σ2( tj2 ) . The new initial
marking has one token in ps′ ; the new
final marking set F′ = F1 ∪ F2. If
ps1 ∈ F1 or
ps1 ∈ F2, then
ps′ ∈ F′ also.
Q.E.D.
Still another way of combining two Petri nets is by allowing
the executions of two systems to occur concurrently.
This allows all possible interleavings of an execution of
one Petri net with an execution of the other Petri net.
Riddle [1972] has introduced the || operator to represent
this concurrency. It can be defined for a, b ∈ Σ
and x1, x2 ∈ Σ* by
| a x1 || b x2 | = | a(x1 || b x2) + b(a x1 || x2) | ||
| a || λ | = | λ || a | = | a |
| L1 || L2 | = | { x1 || x2 | x1 ∈ L1, x2 ∈ L2 } |
It is easily shown that regular, context-sensitive, and type-0 languages are closed under concurrency by demonstrating that the cross product of two finite state machines, linear bounded automata, or Turing machines is still a finite state machine, linear bounded automaton, or Turing machine, respectively. Since the cross product of two pushdown stack automata cannot be transformed into another pushdown stack automaton, context-free languages are not closed under concurrency. For Petri net languages, we have the following theorem.
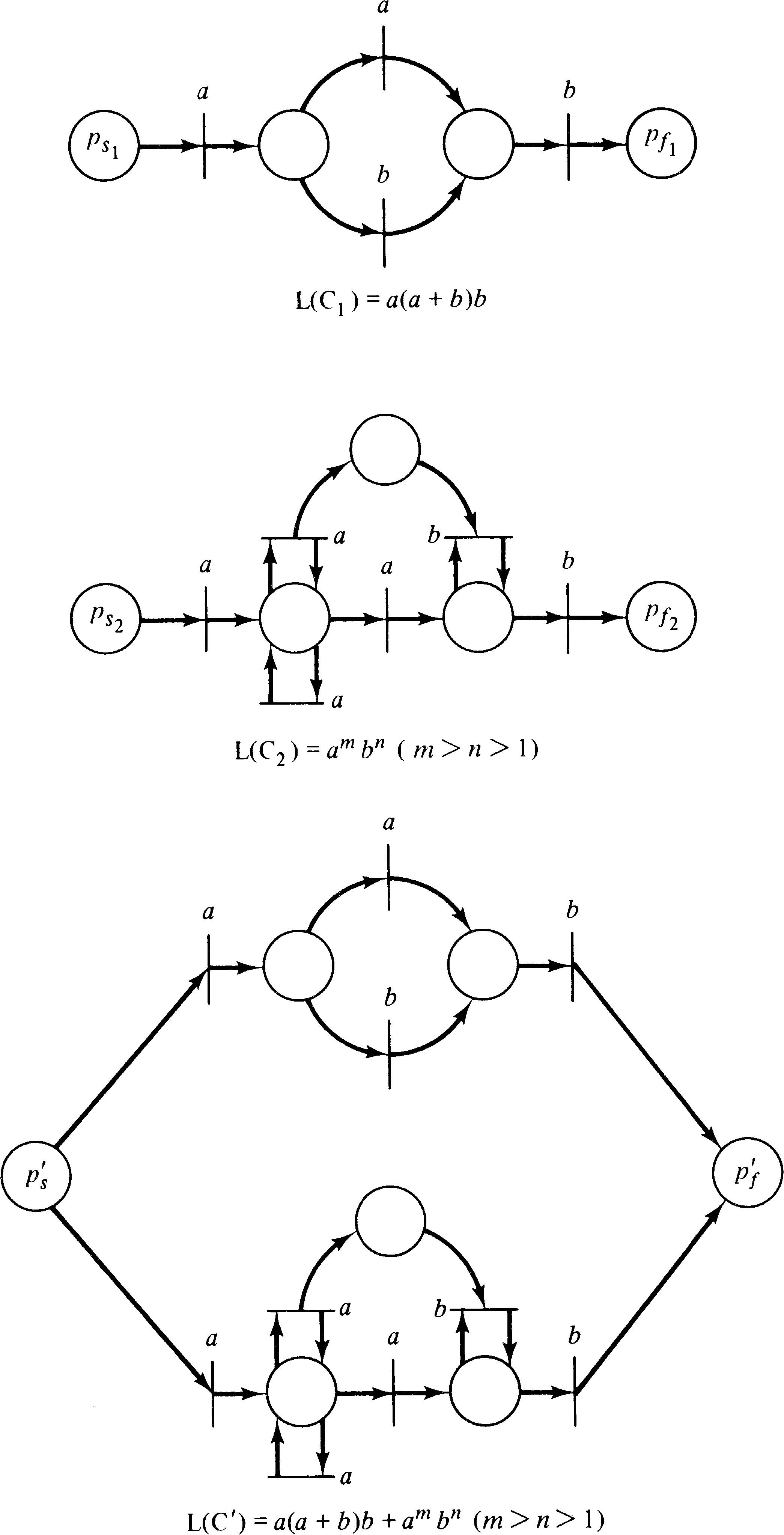
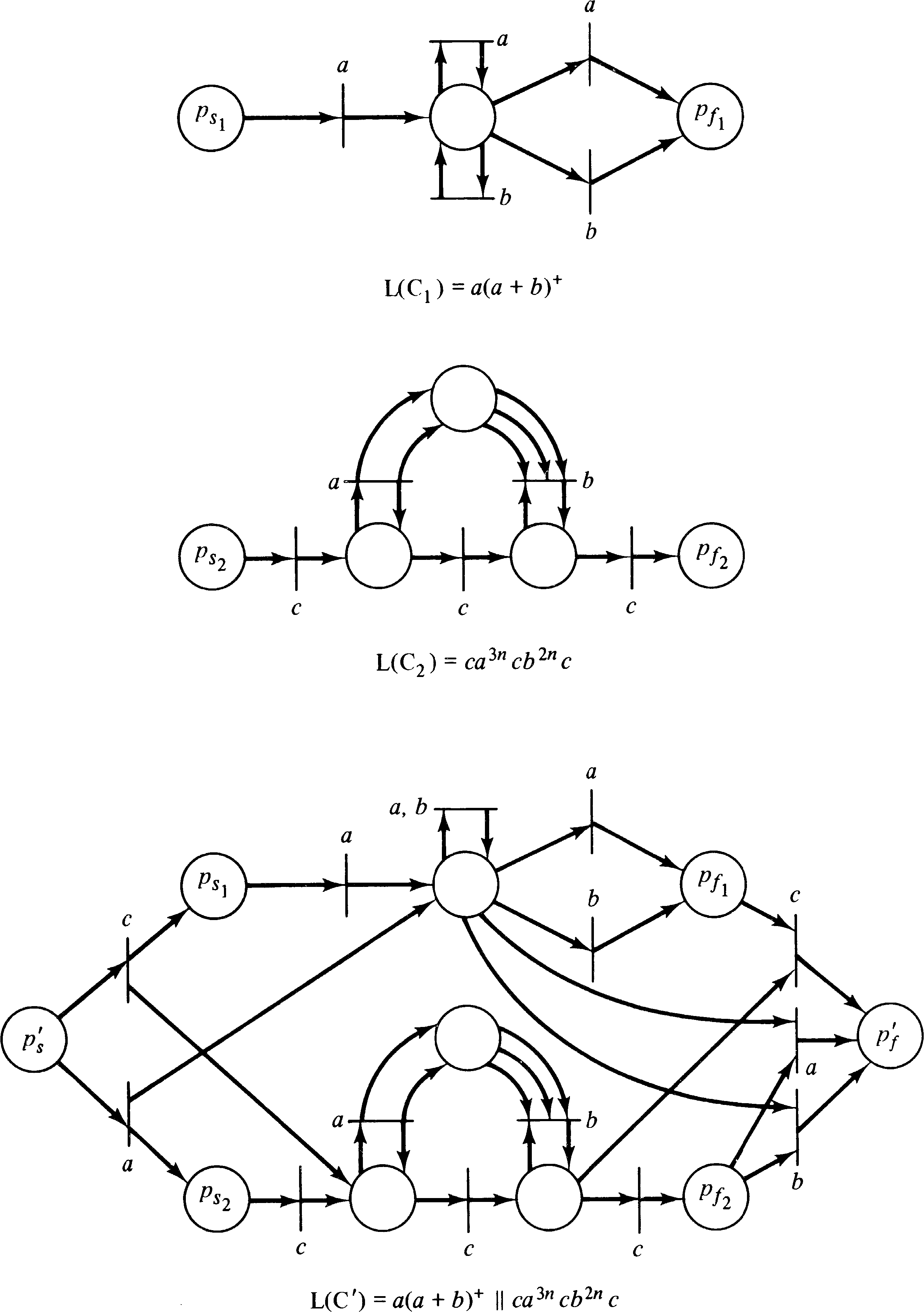
This construction is illustrated in Figure 6.10 for
L1 = a ( a + b )+ and
L2 = c a3n c b2n c.
As with union, the intersection composition is similar to
the set theory definition of intersection and is given for a
Petri net language by
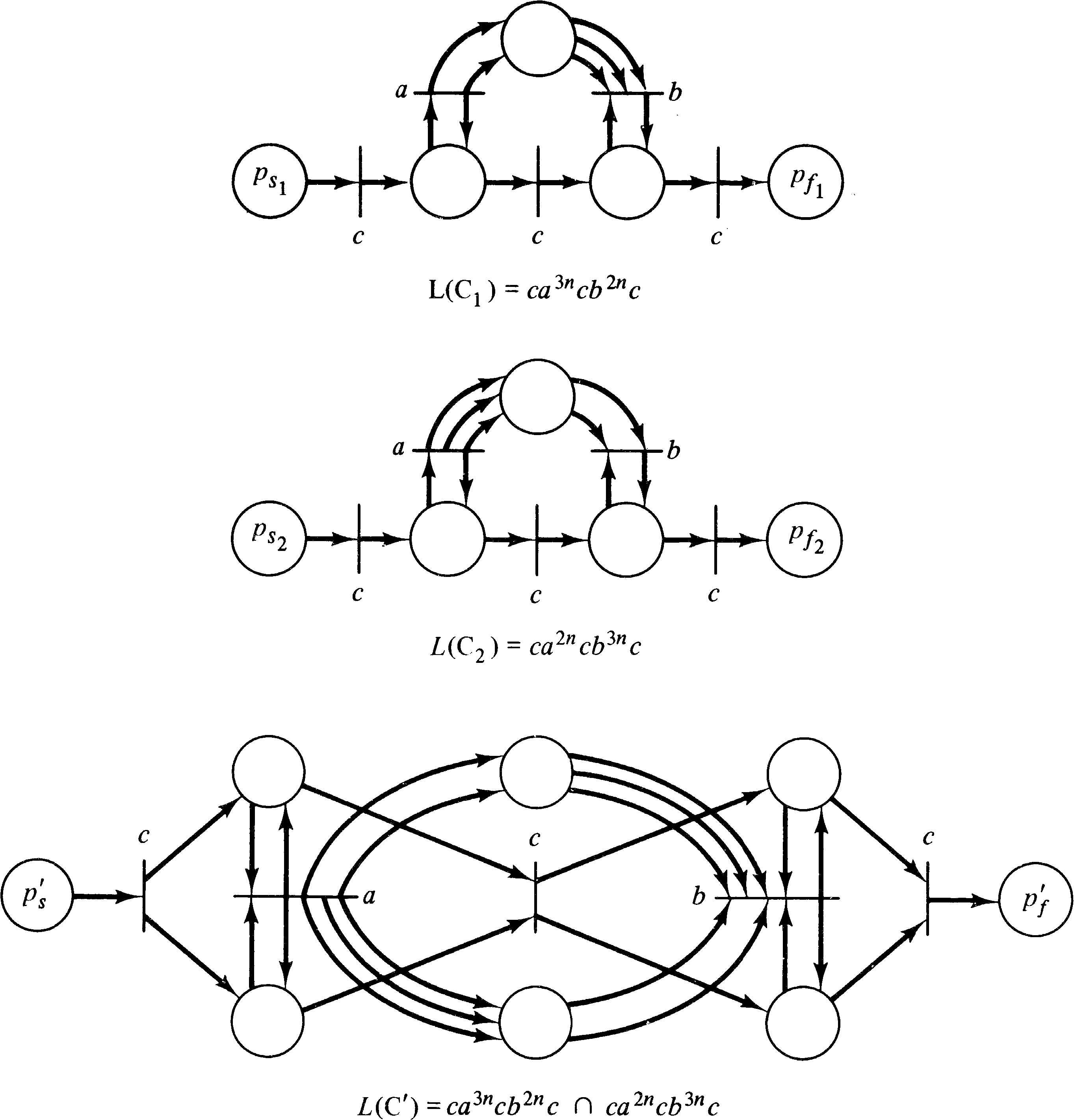
| L1 ∩ L2 | = | { x | x ∈ L1 and x ∈ L2 } |
The construction of a Petri net to generate the
intersection of two Petri net languages is rather complex.
At a given point in the generated string, if a transition fires
in one Petri net, there must be a transition in the other
Petri net with the same label which fires also. When more
than one transition exists in each Petri net with the same
label, we must consider all possible pairs of transitions
from the two Petri nets. For each of these pairs, we create
a new transition which fires if and only if both transitions
fire in the old Petri nets. This is done by making the
input (output) bag of the new transition the bag sum (see the
appendix) of the input (output) bags of the pair of
transitions from the old Petri nets. Thus if
tj ∈ T1 and tk ∈ T2 are such that
σ ( tj ) = σ ( tk ), then we have a
transition tj, k ∈ T′
with I′ ( tj, k ) = I1( tj ) + I2( tk ) and
O′ ( tj, k ) = O1( tj ) + O2( tk ) .
Some of these transitions have inputs which include the
start place. If for a transition tj, k
in T′, as defined above,
I′ ( tj, k ) = { ps1, ps2 }, then we
replace this transition with a new transition
tj, k′, where
I′ ( tj, k′ ) = { ps′ } . This construction essentially
places the two original Petri nets in a lockstep identical
execution mode. This composite Petri net generates the
intersection of L1 and L2. The construction is
demonstrated in Figure 6.11.
Unlike the previous composition operations which we have
examined, the operation of reversal seems to have only
academic interest. The reversal of a sentence
xR is the sentence x with its symbols in the
reverse order. We define this recursively by
| aR | = | a |
| (a x)R | = | xR a |
| LR | = | { xR | x ∈ L } |
The construction is trivial. The start and final markings
are interchanged, and the input and output bags for each
transition are also interchanged and
L ( γ′ ) = L ( γ )R.
This merely runs the Petri net backwards
and reverses all generated strings.
6.5.6. Complement
The complement L of a language L over an alphabet
Σ is the set of all strings in Σ* which are
not in L. This can be expressed as
| L | = | Σ* − L |
| L | = | { x ∈ Σ* | x \o′/∈′ L } |
Closure under complement for the L-type Petri net languages
is an open problem. However, Crespi-Reghizzi and Mandrioli [1977]
have shown that some Petri net languages are not closed
under complement; that is, there are Petri net languages
whose complement is not a Petri net language.
6.5.7. Repeated Composition
So far we have considered the operations of union, intersection, concatenation, concurrency, reversal, and complement. Except for the last operation, we were able to give constructions that show that Petri net languages are closed under these operations. From these results we can immediately derive the following corollary.
A new operation can be defined by removing the constraint
that only a finite number of compositions be allowed. The
indefinite concatenation (Kleene star) of a language
is the set of all concatenations (of any length) of elements
from that language. This is represented by L* and is
defined by
| L* | = | L ∪ L L ∪ L L L ∪ ⋯ |
This operation may be of practical use. Indefinite concatenation is similar to the modeling of a loop. Also it is known that regular, context-free, context-sensitive, and type-0 languages are closed under indefinite concatenation [Hopcroft and Ullman 1969]. Thus it is unexpected and perhaps unfortunate that Petri net languages are not closed under indefinite concatenation.
This appears to be due to the combination of the finite nature of Petri nets (finite number of places and transitions) and the permissive nature of the state changes [transitions are allowed (permitted) to fire but cannot be required to do so]. To construct a Petri net to generate the indefinite concatenation of a Petri net language would, in general, require the reuse of some portion of the Petri net. This allows tokens to be generated and left in some of the places which are reused. At a later repetition of the Petri net, these tokens may be used to allow transitions to fire when they should not.
The proof that Petri nets are not closed under indefinite
concatenation appears to be very difficult. Perhaps a
flavor of the approach can be given by considering an
example. We have already seen that
an bn ( n > 1 ) is
a Petri net language. We claim that
( an bn )* is not a Petri
net language. All generators of
( an bn )* must have some
place or set of places that encode the number n for
each portion of the string. These tokens control the
generation of the b symbols. For a Petri net to
generate ( an bn )* it is
necessary to use these places more than once. But since the
net is permissive, there is no way to guarantee that these
places are empty before they are reused. Thus for any Petri
net which attempts to generate
( an bn )* there exists
some i, j, k such that the Petri net also
generates some string of the following form:
| an1 bn1... ani bnj... anj bni... ank bnk |
For readers familiar with the formal language theory of Abstract Families of Languages (AFL) [Ginsburg 1975], it is easy to prove that Petri net languages are not closed under indefinite concatenation. It is well known that the smallest full AFL closed under intersection and containing { an bn } contains every recursively enumerable set. Thus, since Petri net languages are closed under intersection and { an bn } is a Petri net language, if they were closed under indefinite concatenation, they would be such an AFL. However, we know that { w wR } is not a Petri net language (see Section 6.6.2), and so Petri net languages are not closed under indefinite concatenation. This argument is due to Mandrioli.
A subclass of Petri net languages exists which is closed under indefinite concatenation, however. This is the class of Petri net languages for properly terminating Petri nets. Proper termination was defined by Gostelow [1971] for complex bilogic graph models of computation. We borrow his definition and rephrase it in terms of Petri nets as follows.
We notice first that the second part of the definition is not actually a restriction since if the Petri net terminates, then it terminates in a finite amount of time and hence generates only a finite number of tokens. But the first part of the definition is a restriction. We may view the Petri net as a machine which generates strings of symbols. We place a token in the input to the machine, and a string of symbols is printed on a piece of tape for us. Eventually a light may come on saying that the machine has halted (i.e., there are no enabled transitions). In normal use, before we can use the printed output, we must look inside the machine and check that a final marking has been reached. If a final marking has not been reached, then we must reject the output and try again. If the Petri net is properly terminating, then we need not look inside the machine; we are guaranteed that a final marking has been reached.
We can see then how a properly terminating Petri net can be used to construct a Petri net generating the indefinite concatenation of its language. We simply connect the final place to the start place. Since the Petri net is known to be empty whenever a token appears at the final place, no tokens will be left in the Petri net to cause spurious transitions when the Petri net is reused.
Unfortunately, this subclass of Petri nets is not very
interesting since we can show that all properly terminating
Petri nets are finite state machines and vice versa. Hence
the Petri net languages of properly terminating Petri nets
are regular languages, and it is already known that this
class of languages is closed under indefinite concatenation.
Thus we see that the properties of systems modeled by Petri
net languages are limited to finite repetitions of smaller
subsystems or indefinite repetitions of smaller finite
subsystems.
6.5.8. Substitution
We have mentioned that systems can be designed and modeled hierarchically by Petri nets. This involves first specifying a rough outline of the system and then successively refining this outline by substituting for operations the definitions of these operations in terms of other operations. With Petri nets, this refinement may take the form of substituting a complete Petri net for a transition or a place. The latter is very straightforward; we therefore restrict our attention to considering the problem of substituting a subnet for a transition (or operation) of a Petri net.
When it is desired to substitute a Petri net for an operation in another Petri net, this can be considered as a composition of the Petri net languages of the two Petri nets. Since the operation is represented by a symbol from Σ, substitution of a Petri net language L2 for a symbol σ in another Petri net language L1 is defined as the replacement of all occurrences of σ in L1 by the set of strings L2. Petri net languages are closed under substitution if the result of a substitution involving a Petri net language is also a Petri net language. Variations on substitution include finite substitution, where L2 must be a finite set of strings, and homomorphism, where L2 is a single string.
Again, unfortunately, we have a negative result. Petri net languages are not closed under general substitution. This is shown immediately by letting L1 = c* and substituting L2 = an bn for c in L1. The problem is again caused by the possible reuse of a Petri net. For finite substitution and homomorphism, however, we see that L2 is a regular language, and hence a properly terminating Petri net can be constructed to generate it. This yields the following theorem and corollary.
Having considered the properties of Petri net languages as a
class of languages, we turn to investigating the
relationship between Petri net languages and other classes
of languages. In particular, we consider the classes of
regular, context-free, context-sensitive, and type-0
languages.
6.6.1. Regular Languages
One of the simplest and most studied classes of formal languages is the class of regular languages. These languages are generated by regular grammars and finite state machines. They are characterized by regular expressions. Problems of equivalence or inclusion between two regular languages are decidable, and algorithms exist for their solution [Hopcroft and Ullman 1969]. With such a desirable set of properties, it is encouraging that we have the following theorem.
The proof of this theorem is based on the fact that every regular language is generated by some finite state machine and we have shown (Section 3.3.1) that every finite state machine can be converted to an equivalent Petri net.
The converse to this theorem is not true. Figure 6.12
displays a Petri net which generates the context-free
language { an bn | n > 1 } .
Since this language is not regular, we know that not
all Petri net languages are regular languages.
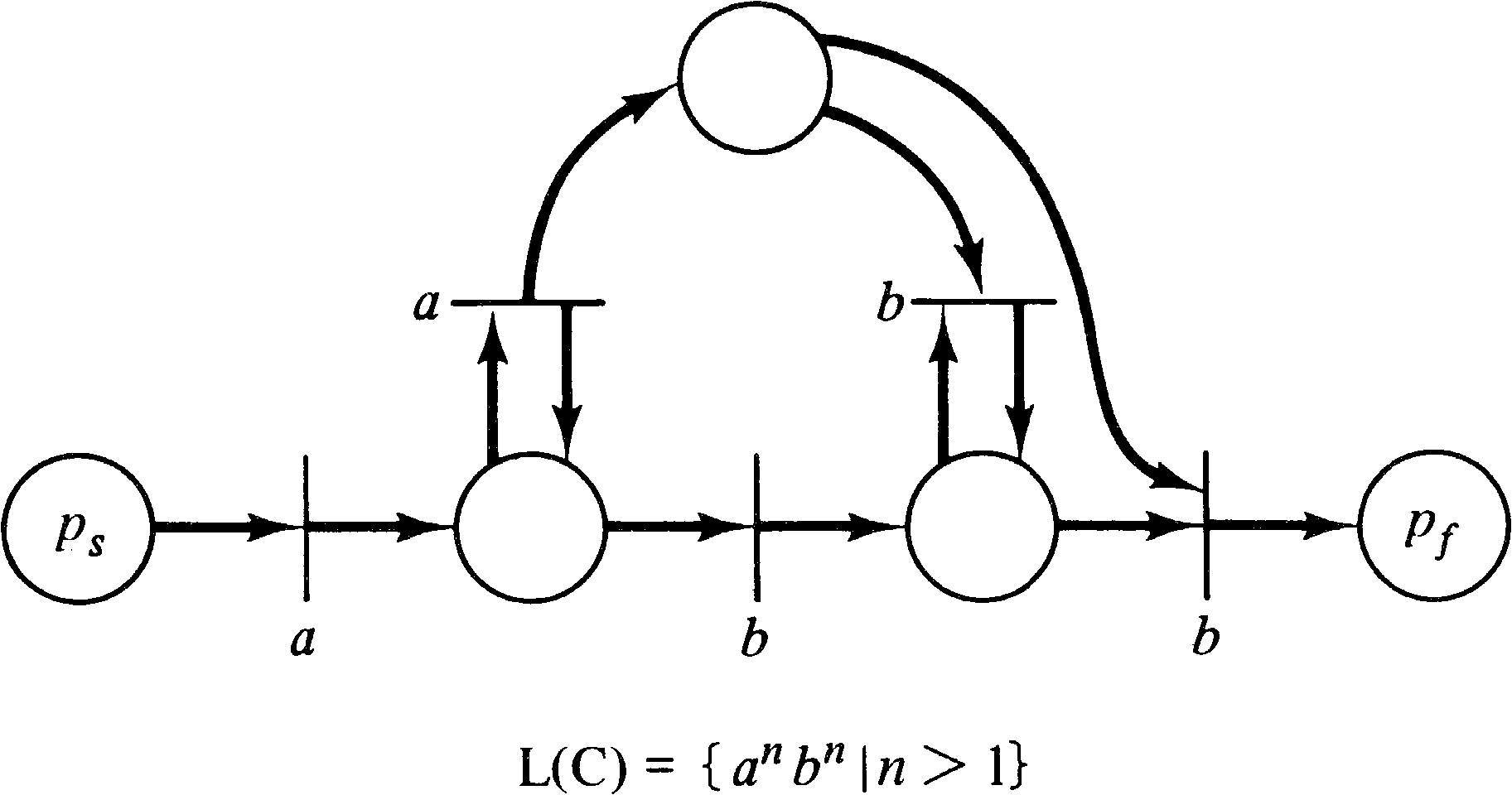
Figure 6.12 demonstrated that not all Petri net languages
are regular languages by exhibiting a Petri net language
which was context-free but not regular. Figure 6.13 shows
that not all Petri net languages are context-free by
exhibiting a Petri net language which is context-sensitive
but not context-free. Unlike the situation with regular
languages, however, there also exist context-free languages
that are not Petri net languages. An example of such a
language is the context-free language
{ w wR | w ∈ Σ* } .
This results in the
following theorem.
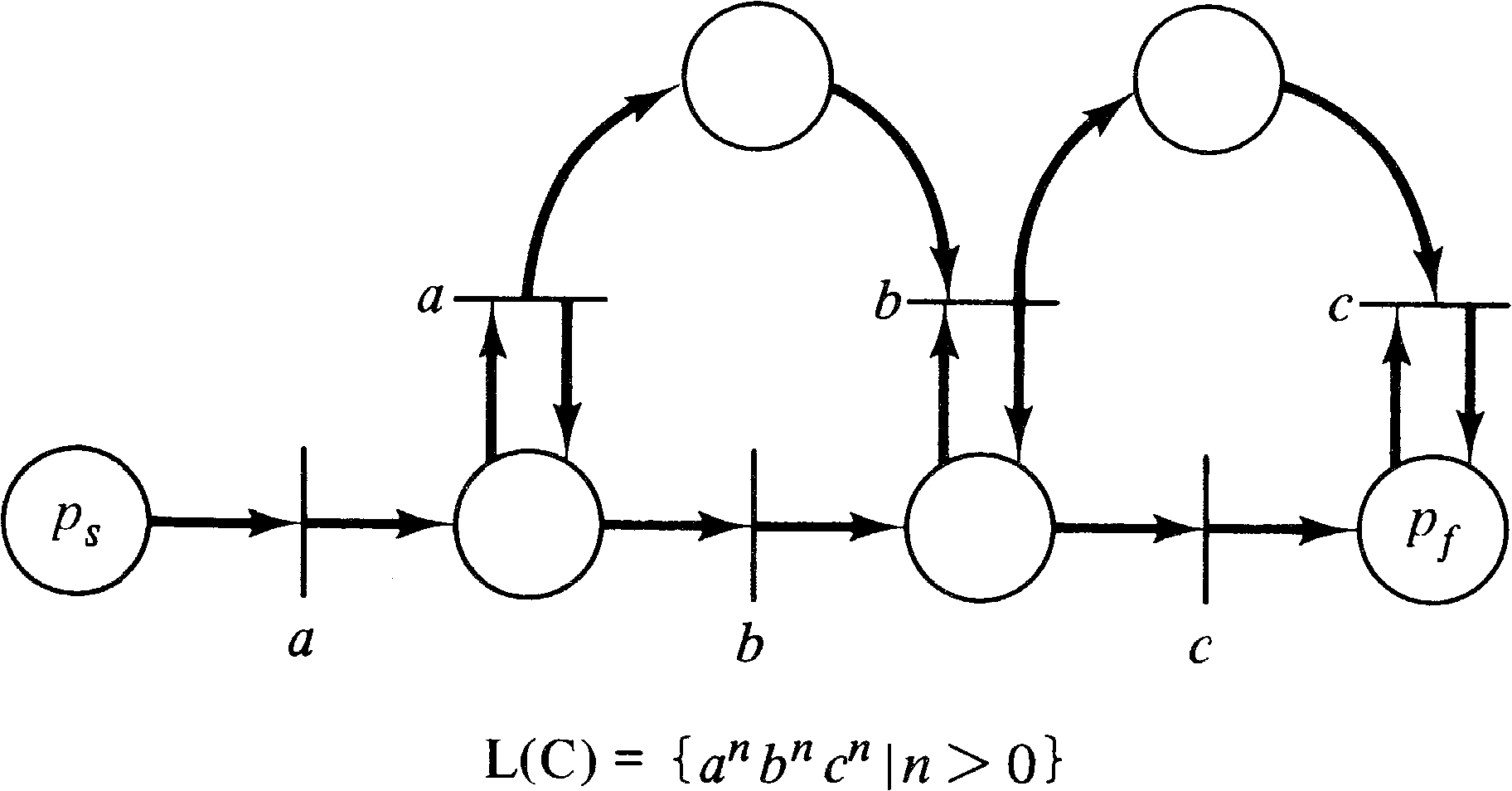
| δ(μ, x1 x2R) | = | δ(δ(μ, x1), x2R) |
| = | δ(δ(μ, x2), x2R) | |
| = | δ(μ, x2 x2R) ∈ F |
In Section 4.2.2, we showed that for each transition
tj there exists a vector
vj = e [ j ] ⋅ D
such that if δ ( q, tj ) is defined,
then the value of δ ( q, tj ) is
q + vj. Thus after r inputs, we have a
state qr where
| qr | = | μ + | Σ | vij |
| j |
| qr | = | μ + | Σ | fj vj |
| j |
| Σ | fj | = | r |
| j |
At best the vectors
v1, v2, …, vm
will be linearly independent, and each firing
vector ( f1, f2, …, fm )
will represent a unique state
qr. Since the sum of the coefficients is
r, the vector
( f1, f2, …, fm )
is a partition of the integer
r into m parts. Knuth [1973] has shown that the
number of partitions of an integer r into m
parts is
| r + m − 1 |
| m − 1 |
&leftbigparen;
|
= |
|
< | (r + m)m |
| r + m − 1 |
The proof that w wR is not a Petri net language sheds some light on the limitations of Petri nets as automata and hence on the nature of Petri net languages. Petri nets are not capable of remembering arbitrarily long sequences of arbitrary symbols. From the proof, we see that Petri nets can remember sequences of bounded length (but so can finite state machines). Another feature of Petri nets is the ability to remember the number of occurrences of a symbol, such as in an bn cn, to an extent that regular and context-free generators cannot. However, a Petri net cannot simulate the power of a pushdown stack, which is necessary to generate context-free languages. The rate of growth of the reachable state space for a Petri net is combinatorial with the length of the input and not exponential as needed for a pushdown stack.
The reason that Petri nets are able to generate languages which a pushdown stack cannot generate despite the smaller state space is because of the more flexible interconnections between states in the Petri net compared to the restrictive paths between states allowed in a pushdown stack automaton. This results from restricting the pushdown stack automaton to accessing only the top of the stack, while the Petri net can access any of its counters at any time.
Having shown that not all context-free languages are Petri
net languages and not all Petri net languages are
context-free, the question arises as to what is the class of
languages which are both context-free and Petri net
languages? At present we cannot fully answer this question,
but we can give an indication of some of the members of this
intersection. One subset of both context-free and Petri net
languages is, of course, the class of regular languages.
Another subset is the set of
bounded context-free languages
investigated by Ginsburg [1966].
6.6.3. Bounded Context-free Languages
A context-free language L is bounded context-free
if there exist words (or strings)
w1, w2, …, wm
from Σ* such that
| L ⊆ w1* w2*... wm* |
Bounded context-free languages are characterized by the following theorem of Ginsburg [1966, Theorem 5.4].
We have already shown (Section 3.3.1) that every finite state machine and hence every regular language and every finite subset of Σ* is a Petri net language. In Sections 6.5.1 and 6.5.2 we showed that Petri net languages are closed under concatenation and union. Thus we have only to show that 3 above is satisfied for Petri net languages. To show this, we would construct a Petri net γ′ = (C′, Σ, μ′, F′ ) which generates the Petri net language { xi W yi | i ≥ 0 } given standard form Petri nets γx = (Cx, Σ, μx, Fx ), γy = (Cy, Σ, μy, Fy ), and γW = (CW, Σ, μW, FW ) that generate x, y, and W, respectively. γ′ combines the Petri nets γx, γy, and γW and a new place p so that each time γx is executed, a token is placed in p. The place p counts the number of times γx is executed. After γx has executed as many times as it wishes, γW is executed, and finally γy is executed repeatedly, removing one token from p for each repetition. Since the input string is correctly generated only if the Petri net is empty (except for F′ which is defined to be Fy ), we are assured that the number of executions of γx and γy are equal.
This construction, which is demonstrated in Figure 6.14, for
x = a b, y = b ( a + b ),
and W = b+ a, shows that
{ xi W yi | i ≥ 0 }
is a Petri net language. Thus any
bounded context-free language is a Petri net language.
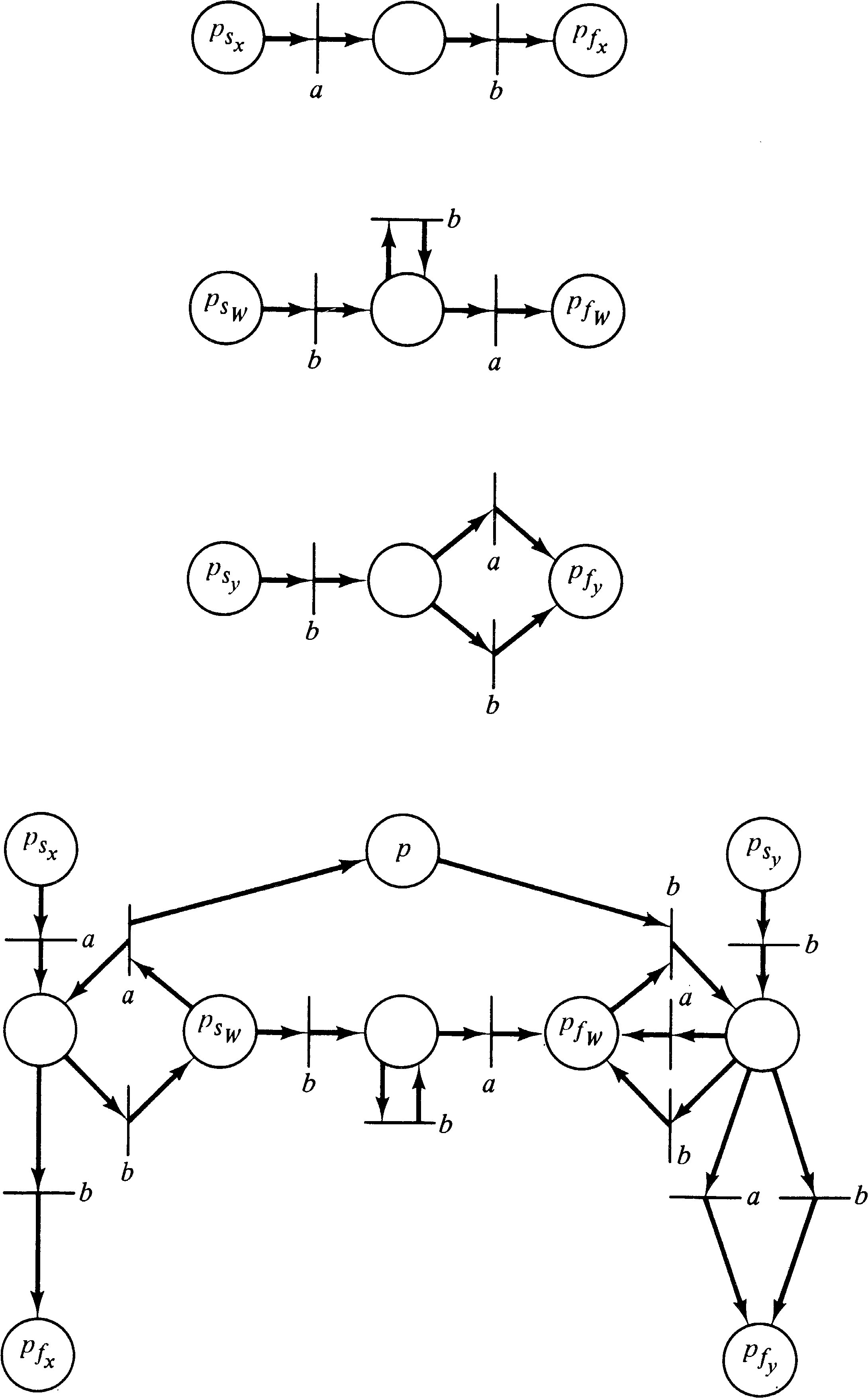
Are there context-free languages which are also Petri net languages but not bounded? Unfortunately, the answer is yes. Ginsburg shows that the regular expression ( a + b )+ is not a bounded context-free language. Since this language is a context-free Petri net language, we see that bounded context-free languages are only a proper subset of the family of context-free Petri net languages. We also exhibit the language { ( a + b )+ an bn | n > 1 } which is a context-free Petri net language but is neither bounded nor regular. Further research is needed to completely characterize the set of context-free Petri net languages.
The presence of both regular sets and bounded context-free
languages as subsets of the class of Petri net languages is
encouraging since both classes of languages have several
desirable properties and some nice analysis characteristics.
6.6.4. Context-sensitive Languages
We have investigated the relationship between Petri net languages and regular languages and between Petri net languages and context-free languages. Now we turn to context-sensitive languages. Figure 6.13 has shown that some Petri net languages are context-sensitive; below we prove that all Petri net languages are context-sensitive. Since we know that all context-free languages are also context-sensitive and that there exist context-free languages which are not Petri net languages, we know that there exist context-sensitive languages which are not Petri net languages. Thus the inclusion is proper.
The proof that all Petri net languages are context-sensitive is rather complex. There are two ways to show that a language is context-sensitive: Construct a context-sensitive grammar which generates it, or specify a nondeterministic linear bounded automaton which generates it. Peterson [1973] has shown how to define a context-sensitive grammar to generate a Petri net language; here we indicate why a linear bounded automaton can generate a Petri net language.
A linear bounded automaton is similar to a Turing machine. It has a finite state control, a read/write head, and a (two-way infinite) tape. The limiting feature which distinguishes it from a Turing machine is that the amount of tape which can be used by a linear bounded automaton to generate a given input string is bounded by a linear function of the length of the input string. In this sense it is similar to the pushdown stack automaton used to generate context-free languages (since the maximum length of the stack is bounded by a linear function of the input string) except that the linear bounded automaton has random access to its memory, while the pushdown automaton has access to only one end of its memory.
To generate a Petri net language, one can simulate the Petri
net by remembering, after each input, the number of tokens
in each place. How fast can the number of tokens grow as a
function of the input? Consider the number of tokens after
r transition firings. This number, denoted by
c, is, for a transition sequence
ti1 ti2... tir,
| c | = | 1 + | Σ | | O(tij) | − | I(tij) | |
| j |
| l | = | max | | O(tj) | − | I(tj) | |
| tj ∈ T |
| c | = | 1 + | Σ | | O(tij) | − | I(tij) | |
| j | ||||
| ≤ | 1 + r ⋅ l | |||
With this proof, we have shown that all Petri net languages
are context-sensitive languages. We summarize the results
of our investigation into the relationship between the class
of Petri net languages and other classes of languages in the
graph and Venn diagram of Figure 6.15.
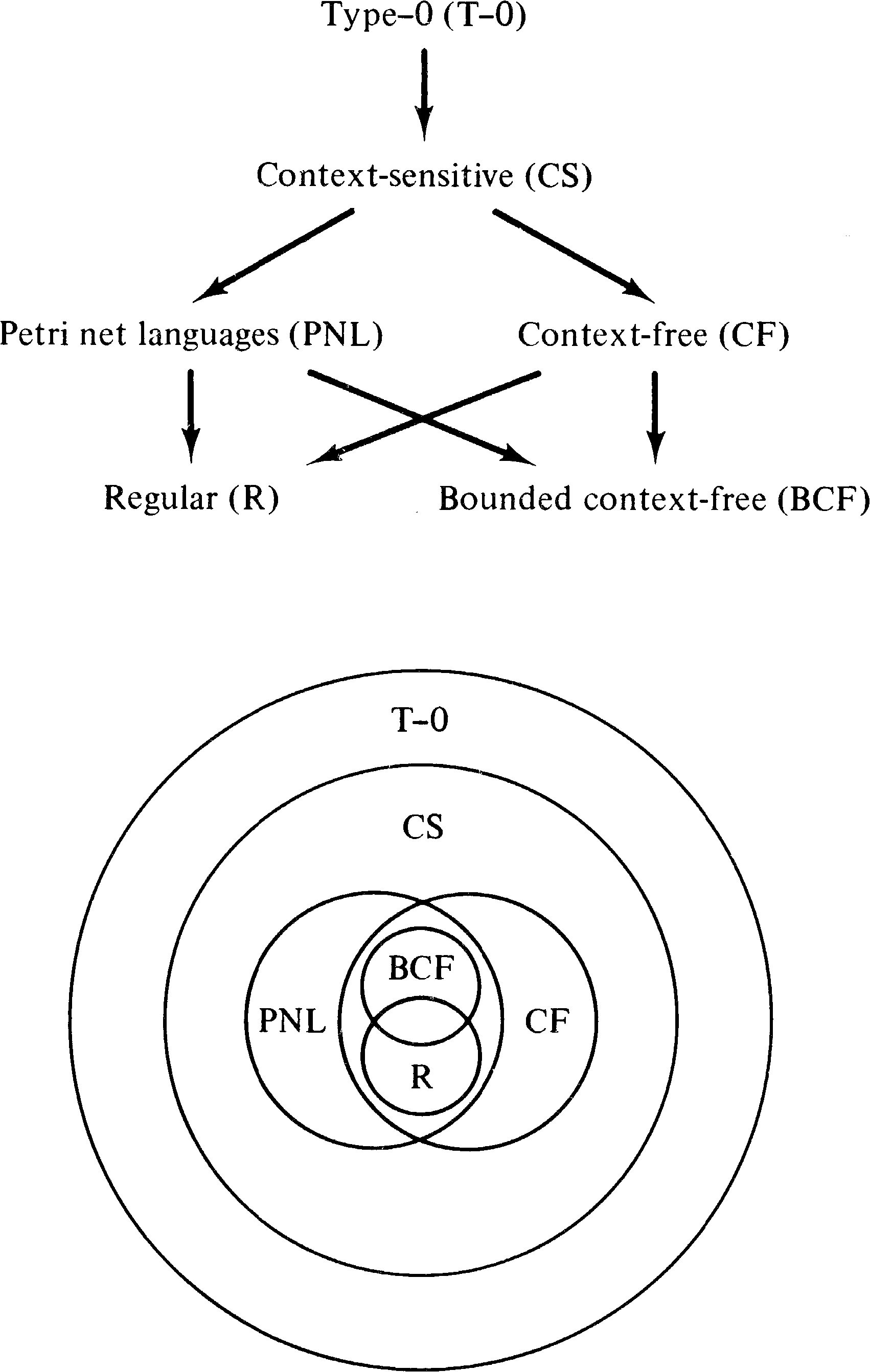
Figure 6.16 summarizes the properties of Petri net
languages. It is drawn from [Peterson 1976] and [Hack 1975b].
| Lf | L | Lλ | Pf | P | Pλ | ||
| Closure under | |||||||
| Union | No | Yes | Yes | ? | Yes | Yes | |
| Intersection | Yes | Yes | Yes | Yes | Yes | Yes | |
| Concatentation | ? | Yes | Yes | ? | Yes | Yes | |
| Concurrency | ? | Yes | Yes | ? | Yes | Yes | |
| Regular substitution | No | λ-free | Yes | ? | Prefix | Prefix | |
| Inverse homomorphism | Yes | Yes | Yes | Yes | Yes | Yes | |
| Kleene star (iteration) | ? | No | No | ? | ? | ? | |
| Complement | No | ? | No | No | ? | No | |
| Contains regular languages | No | Yes | Yes | No | Prefix | Prefix | |
| Symmetric difference with context—free languages (non-empty) | Yes | Yes | Yes | Yes | Yes | Yes | |
| Is context-sensitive | Yes | Yes | ? | Yes | Yes | ? | |
Most of the results presented here have been developed in both [Peterson 1976] and [Hack 1975b]. In addition, Hack has investigated a number of decidability problems for Petri net languages. The membership problem [Is a string α an element of a language L ( γ ) ?] is decidable, while the emptiness problem [Is the language L ( γ ) empty?] can be easily seen to be equivalent to the reachability problem. It is undecidable if two Petri net languages are equal or if one is contained within the other (the equivalence and inclusion problems).
Figure 6.17 summarizes these results.
| L | L | Lλ | Pf | P | Pλ | |
| Decision Problems | ||||||
| Membership | D | D | ? | D | D | D |
| Emptiness | ? | ? | ? | D | D | D |
| Finiteness | ? | ? | ? | D | D | D |
| Equivalence and inclusion | ? | U | U | ? | U | U |
A different approach to the study of Petri nets by the use
of formal language theory has been considered by
Crespi-Reghizzi and Mandrioli [1974]. They noticed the
similarity between the firing of a transition and the
application of a production in a derivation, thinking of
places as nonterminals and tokens as separate instances of
the nonterminals. The major difference is, of course, the
lack of ordering information in the Petri net which is
contained in the sentential form of a derivation. This
resulted in the definition of
the commutative grammars, which are
isomorphic to Petri nets. In addition
Crespi-Reghizzi and Mandrioli considered the relationship of
Petri nets to matrix [Abraham 1970], scattered context, nonterminal
bounded, derivation bounded, equal-matrix, and Szilard
languages. For example, it is not difficult to see that the
class Lf is the set of Szilard languages of matrix
context-free languages [Crespi-Reghizzi and Mandrioli 1977;
Hopner and Opp 1977].
6.8. Further Reading
There are three good studies on Petri net languages.
[Peterson 1976] or [Peterson 1977] is probably the easiest
to get, although [Hack 1975b] is a more rigorous and
complete investigation. [Crespi-Reghizzi and Mandrioli 1974]
is rather hard to find, but nonetheless it is an excellent
piece of work, quite inventive and well explained.
6.9. Topics for Further Study
Although a good start on research into the properties of Petri nets has been made, much still remains to be done. Of the classes of languages which have been defined, only two, the classes of P-type and L-type languages, have been studied and these only for generalized Petri nets. Several subsets of the set of general Petri nets have been defined, including marked graphs, conflict-free nets, restricted nets, and free-choice nets, as we see in Chapter 7. Each of these classes of Petri nets presumably has its own class of languages with its own distinctive properties. Some investigation of these classes has been done. It is known [Hack 1975b] that the classes L, Lλ, G, Gλ, P, and Pλ for restricted Petri nets [no self-loops, no multiple arcs; i.e., all bags are sets, and for every tj, I ( tj ) ∩ O ( tj ) = ∅ ] are identical to the corresponding classes for generalized Petri nets. It is also not difficult to see that the classes Lλ, Gλ, and Pλ are not changed by restricting the nets to free-choice nets (see Section 7.4.3). This still leaves many interesting cases to be studied. In particular, the languages generated by marked graphs, or by conflict-free nets in general, seem to have a structure reminiscent of deterministic context-free languages, and their study should be very promising.
Another important open problem concerns the distinction between λ -free languages ( L, P, …) and unrestricted languages ( Lλ, Pλ, …). It is not known whether L = Lλ or not, for example.
| Home | Comments? |